谷歌的下一个Transformer?大模型永久记忆难题的破解尝试

当ChatGPT在对话窗口关闭后立即忘记所有交互内容,当Gemini无法记住用户昨天教给它的业务规则,整个AI行业都在面对一个令人沮丧的事实:我们构建的智能体患有严重的"顺行性遗忘症"。它们拥有海量的预训练知识,却无法形成新的长期记忆。谷歌研究团队在NeurIPS 2025会议上发表的论文《Nested Learning: The Illusion of Deep Learning Architectures》提出了一个激进的解决方案——也许问题不在于缺少记忆模块,而在于我们对AI架构本质的理解从一开始就错了。
论文第一作者、谷歌研究员Ali Behrouz用电影《记忆碎片》中的疾病来比喻当前AI的困境。患有顺行性遗忘症的主角记得发病前的一切技能和知识,但无法形成任何新记忆,每隔几分钟就会将刚发生的事情完全遗忘。现代大语言模型的状态与此惊人相似:无论用户在对话中教给它多少专业知识或纠正多少次错误,这些信息都只停留在短暂的上下文窗口中。一旦会话结束或显存清空,模型立即回到出厂状态,丝毫未因交互而进化。
这种遗忘并非技术实现的疏忽,而是当前深度学习范式的结构性缺陷。在标准的Transformer架构中,注意力机制提供了极快的上下文学习能力,能瞬间响应输入的每个词元,但这种记忆只在推理过程中存在。另一端,前馈神经网络承载了模型的绝大多数参数和长期知识,但它的更新频率是零——除非耗费巨资进行全量微调,否则这部分永远冻结。在这两个极端之间,存在着一个巨大的真空地带,没有任何机制能够以中等频率捕捉和沉淀知识。

从二元对立到频谱统一
谷歌团队的核心洞察在于质疑一个长期以来被视为理所当然的假设:AI的"架构"与"优化器"是两个截然不同的实体。传统观点认为,架构如Transformer是静态的推理骨架,在训练完成后就固化;而优化器如Adam是动态的训练工具,仅在工厂中雕刻模型,产品发布后就被丢弃。这种二元划分造就了当前AI的"精神分裂"状态。
Nested Learning范式试图打破这一界限。研究团队提出,架构和优化器本质上执行的是同一类任务:以不同频率压缩和记忆信息。传统模型记忆的是训练数据中的模式,而优化器记忆的是梯度信息,即"上次在哪里犯错、下次如何修正"。既然两者都在进行记忆和状态更新,为什么要人为割裂它们
论文引用了神经科学中的半球切除术案例来支持这一统一性假设。医学研究发现,即使切除一半大脑来治疗严重癫痫,剩余的脑组织也能通过重组资源接管几乎全部功能,患者依然能正常生活。这说明大脑并非由功能固定的专用模块组成,神经组织是通用的、可复用的。同样,AI架构中也不应该存在严格的功能边界,而应该是一个连续的、不同频率嵌套运作的统一系统。

基于这一理论,研究团队提出了HOPE框架,全称High-order Optimization and Expressivity。这个名字暗含寓意,因为它确实为解决AI记忆难题带来了希望。HOPE的设计灵感来自人类大脑的双记忆系统:海马体负责快速编码新信息,大脑皮层负责长期存储和整合知识。这两个系统并非孤立运作,而是通过不同频率的神经振荡协同工作。
快慢系统的工程实现
HOPE的快系统采用了Titans架构,这是Ali Behrouz此前的另一项研究成果。Titans可以理解为一种增强型循环神经网络,但关键特性是其自我修改能力。传统RNN在处理序列时被动地应用固定的权重矩阵,而Titans能够根据当前上下文实时生成本步计算所需的键值对,甚至动态决定这次更新的学习率。这种主观能动性使其能够敏锐判断输入信息的重要性,快速形成短期记忆,就像海马体捕捉当下经验一样。
真正颠覆性的创新在于慢系统——连续记忆系统CMS。在传统架构中,前馈网络的参数要么完全冻结,要么全部更新,是一个非黑即白的选择。CMS打破了这一束缚,将前馈层切分为多个频率层级,如同不同转速的齿轮系统:高频层可能每处理数百个词元就更新一次,用于吸收对话中的新定义;中频层可能每处理数万词元更新,用于适应新项目背景;低频层几乎不更新,稳固保存语法和常识。

Ali Behrouz 在 NeurIPS 2025 现场讲解Nested Learning。
这种分层设计的核心价值在于避免灾难性遗忘。新知识优先存储在高频层,不会惊扰深层的旧知识。随着时间推移,真正重要的信息才会像沙漏中的沙子缓慢沉淀到底层。这复刻了人类记忆的巩固过程:短期记忆在睡眠中逐渐转化为长期记忆,而非瞬间覆盖。
为配合这套复杂的记忆系统,团队设计了M3优化器,全称Multi-scale Momentum Muon。既然模型分了层,优化器为什么不能分层M3采用嵌套动量结构,快动量关注局部梯度景观,慢动量把握全局损失地形。这使得训练过程本身也拥有了多尺度的记忆能力。实验数据显示,M3在ImageNet图像分类和大语言模型训练任务中都展现出更快的收敛速度和更优的最终性能。
工程落地的现实挑战
对于工业界开发者,HOPE最诱人的特性可能是其向后兼容能力。论文提到的Ad-hoc Level Stacking技巧允许直接改造现有预训练模型,无需从头训练。开发者可以将一个标准Llama或Qwen模型的不同层指定为不同更新频率,浅层设为高频以捕捉新知,深层保持低频维持稳定性。这种"原地升级"的可能性大幅降低了技术迁移成本。
然而,这种范式转移也引发了激烈争论。支持者将其视为"Attention Is All You Need V2",认为自我修改能力赋予了AI某种元认知,即学习如何学习的能力,这是从被动拟合到主动适应的质变。实用主义者看到了解决企业AI部署痛点的曙光:如果模型能在业务流中自然学习新规则而不遗忘旧制度,将彻底改变AI的更新维护模式。

Google 将人脑电波的频率机制引入了 AI 架构设计,构建了不同更新频率的层级
批评声音同样强烈。部分研究者质疑论文将随机梯度下降解释为"联想记忆"的数学论证虽然精彩但缺乏严格的收敛性保障。更多工程师担心,嵌套优化的复杂性会让超参数调优难度呈指数级上升。调试一个Adam优化器已经足够困难,现在需要同时协调多个不同频率的"大脑"层级,这可能导致实际应用中的不可控性。
还有学者指出,论文在某种程度上混淆了两个概念:连续学习的实用性问题与架构统一性的理论问题。即使嵌套优化理论成立,在实际部署中让模型持续更新仍面临数据隐私、计算成本和稳定性风险等工程挑战。一个在用户交互中不断自我修改的AI系统,如何确保不会被恶意输入"污染"如何在边缘设备上实现实时的多尺度更新这些问题论文并未充分讨论。
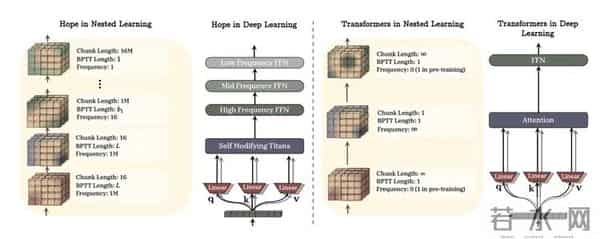
左侧的 HOPE 架构拥有丰富的中间层级
从静态产品到动态生命
将争议放在一边,Nested Learning的最大价值或许在于提出了一个深刻的哲学命题:智能是静态结构的产物,还是动态过程的涌现过去十年,深度学习的主流范式是通过堆叠更多层、增加更多参数来提升能力,这是一种物理深度的暴力美学。而嵌套学习暗示,真正的"深度"可能不在物理层数,而在优化过程的嵌套层级。
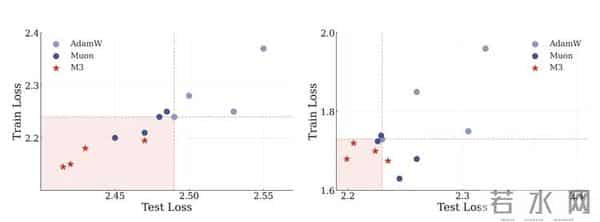
M3 优化器在 ImageNet 训练任务中,展现出了更快的收敛速度和更低的 Loss
论文中一个极其激进的断言是:"预训练本身就是一种超长上下文的情境学习。"这句话模糊了训练与推理的边界。在嵌套学习的愿景中,没有所谓的"训练完成"这一刻,模型在与用户交互的每一秒都在以某种频率微调自己的突触。它不再是出厂即固化的工具,而是在数据流中不断呼吸、代谢、进化的有机体。
这种连续学习的理想在理论上令人向往,但在实践中仍有漫长道路。即使HOPE框架能够技术上实现多尺度记忆,如何控制学习的方向和速度仍是开放问题。人类大脑的学习过程受到情感、注意力、睡眠等多重机制调控,确保重要信息被保留而无关细节被过滤。AI系统如果缺乏类似的调控机制,可能会在信息洪流中迷失方向,或者将噪声误认为信号。
从更宏观的视角看,嵌套学习代表了AI研究从工程优化向认知科学靠拢的趋势。过去几年,Transformer的成功很大程度上依赖于计算规模的暴力扩张,但边际收益已经开始递减。当预训练一个模型的成本达到数亿美元,继续沿着这条路走下去的可持续性受到质疑。嵌套学习提供了另一种可能性:通过更深刻地理解学习本身的机制,设计出更高效、更灵活的架构,而非单纯依赖规模。
Ali Behrouz在NeurIPS现场分享时引用的神经科学证据、数学推导和实验结果,共同指向一个结论:我们对深度学习"深度"的理解可能从根本上就是一种幻觉。真正的智能不是被一次性灌输的知识库,而是在交互中持续生长的动态过程。无论这一理论最终能否成为主流范式,它已经为AI研究打开了一扇新的窗口,让我们重新审视架构、优化器和学习本身的本质关系。从这个意义上说,嵌套学习的价值不仅在于提出了HOPE这个具体框架,更在于挑战了一个被奉为圭臬的基本假设,迫使整个领域思考:也许我们一直在错误的方向上追求深度。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





