PMC群:49周订单规则分配专题
订单数量按规则条件求和
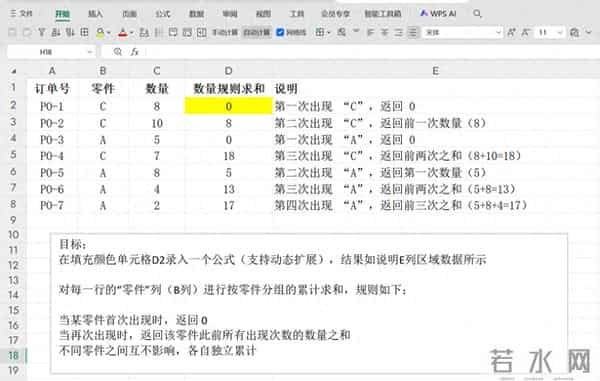
目标:根据订单中的零件类型(B列),对每个零件的订单数量(C列)进行条件求和。具体规则为:
当某零件首次出现时,返回 0后续每次出现该零件时,返回该零件此前所有出现次数的数量总和(不包括当前行的数量)核心函数:- =MAP(B2:B8,LAMBDA(x,LET(a,FILTER(OFFSET(B2:x,,1),B2:x=x),SUM(a)-TAKE(a,-1))))
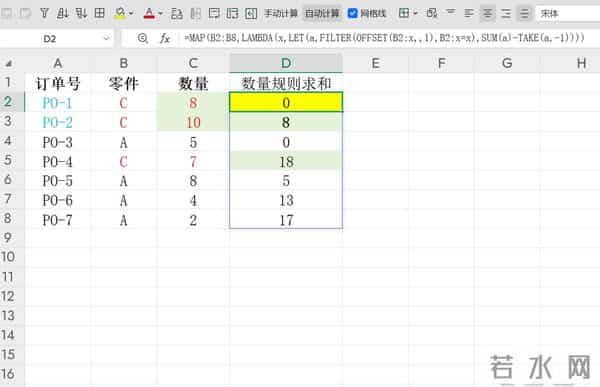
举例:
当处理第4行(x = B4)时:B2:x 表示 B2:B4OFFSET(B2:x,,1) → 相当于 C2:C4注意:OFFSET 在这里被用作动态引用区域,配合 FILTER 使用。
4 FILTER(OFFSET(B2:x,,1), B2:x = x)作用:从 C2:C(当前行及之前)中,筛选出与当前零件 x 相同的所有数量。条件 B2:x = x:检查 B2 到当前行中哪些等于当前零件名。举例(假设当前行是第5行,x = "A"):
B2:B5 = ["C", "C", "A", "C"] → 不,等等,实际要看你的数据假设 B2:B5 = ["C", "C", "A", "A"]x = "A"B2:x = x → [FALSE, FALSE, TRUE, TRUE]OFFSET(...,,1) → C2:C5 = [8, 10, 5, 8]FILTER(C2:C5, [F,F,T,T]) → [5, 8]所以 a = {5; 8}5 SUM(a) - TAKE(a, -1)SUM(a):所有匹配数量的总和(包括当前行)TAKE(a, -1):取数组 a 的最后一个元素(即当前行的数量)相减后 → 得到当前行之前的累计和继续上例:
a = {5; 8}SUM(a) = 13TAKE(a, -1) = 8(当前行的数量)结果 = 13 - 8 = 5 → 正确!这是“A”在第5行之前的累计(只有第3行的5)对于首次出现的零件(如第一个 "C"):
a = {8}(只有当前行)SUM(a) - TAKE(a,-1) = 8 - 8 = 0 → 符合要求!特点:简洁直观,利用 MAP 对每一行独立处理使用 FILTER 获取同零件的所有历史数据SUM(...)-TAKE(...,-1) 实现累计求和(排除当前行)依赖 OFFSET,适用于 Excel 365 环境优点:代码简短,易于理解性能良好,适合中等规模数据集缺点:需要正确处理 OFFSET 的引用逻辑方法二:使用 MAP + SUMIFS + COUNTIF(直接计算型) 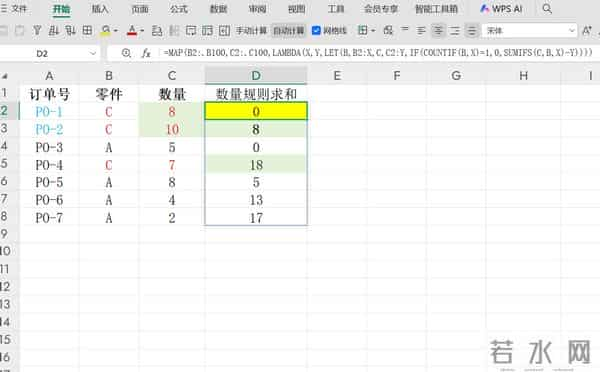
- =MAP(B2:.B100,C2:.C100,LAMBDA(X,Y,LET(B,B2:X,C,C2:Y,IF(COUNTIF(B,X)=1,0,SUMIFS(C,B,X)-Y))))
1 MAP(B2:B100, C2:C100, LAMBDA(X,Y, ... ))
作用:对 B2:B100 和 C2:C100 中的每一行(即每个零件和数量)依次执行一个自定义操作。
X 代表当前正在处理的那一行的零件值(如第3行时,X = B3 的内容,如 "C")。Y 代表当前行的数量值(如 C3 = 10)。相当于一个“循环”:遍历 B2 到 B100,每次把当前行的零件和数量传给 X 和 Y。2 LET(B, B2:X, C, C2:Y, IF(COUNTIF(B,X)=1, 0, SUMIFS(C,B,X)-Y))
作用:定义临时变量 B 和 C,分别表示从 B2 到当前行 X 的零件列和数量列,避免重复引用。
最终返回:如果是该零件首次出现(COUNTIF=1),返回 0;否则,返回该零件此前所有出现次数的数量之和(SUMIFS 减去当前行数量 Y)。3 COUNTIF(B, X)
作用:统计在区域 B(即 B2 到当前行)中,零件 X 出现的次数。
若结果为 1 → 表示是第一次出现 → 返回 0;若大于 1 → 表示已有历史记录 → 进入累计逻辑。4 SUMIFS(C, B, X)
作用:在数量列 C 中,筛选出所有零件等于 X 的行,并求和。
包括当前行的数据,因此需要减去 Y 才能得到“历史累计”。5 SUMIFS(C, B, X) - Y
作用:计算该零件在当前行之前的所有数量总和。
示例:若某零件前两次出现数量为 8 和 10,当前为 7,则此表达式返回 18(8+10),即历史累计。6 IF(COUNTIF(B,X)=1, 0, SUMIFS(C,B,X)-Y)
作用:综合判断是否首次出现。
是 → 返回 0;否 → 返回历史累计和。完美实现“首次为0,后续为历史累计”的业务规则。特点:直接利用 SUMIFS 和 COUNTIF 进行条件统计COUNTIF 判断是否为首行,是则返回 0SUMIFS(...)-Y 实现累计求和(排除当前行)优点:不依赖动态数组函数,兼容性好直观易懂,便于调试缺点:可能需要多次遍历数据,性能稍低方法三:使用 REDUCE + VSTACK + FILTER(逐步累加型) 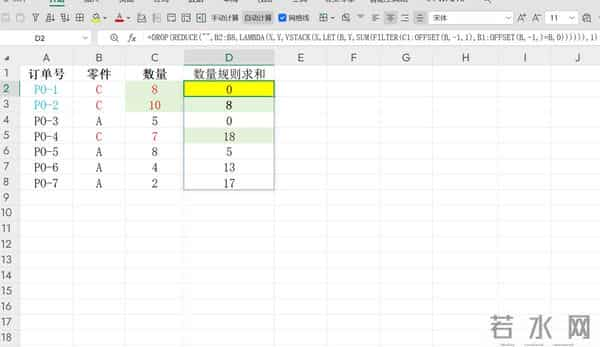
- =DROP(REDUCE("",B2:B8,LAMBDA(X,Y,VSTACK(X,LET(B,Y,SUM(FILTER(C1:OFFSET(B,-1,1),B1:OFFSET(B,-1,)=B,0)))))),1)
1 REDUCE("", B2:B8, LAMBDA(X, Y, ... ))
作用:对 B2:B8 中的每一行逐个处理,从初始值 "" 开始,通过累积方式构建一个结果数组。
X 是上一轮累积的结果(初始为空)Y 是当前正在处理的零件值(如第3行时,Y = B3 = "C")每次迭代都将新计算出的值“堆叠”到 X 上,最终形成完整结果2 VSTACK(X, ...)
作用:将当前累积结果 X 与新计算出的值垂直拼接(即“追加一行”)。
例如:若 X 是 {0; 8},新值是 18,则 VSTACK 后变为 {0; 8; 18}这样逐步构建出整列的累计结果3 LET(B, Y, SUM(FILTER(C1:OFFSET(B,-1,1), B1:OFFSET(B,-1,) = B, 0)))
作用:为当前零件 Y 计算其此前所有出现的数量之和(不含当前行)。
B 被设为当前零件值 Y(如 "C")OFFSET(B, -1, 1) 表示:从当前单元格 B(即某行的 B 列)向上偏移 1 行、向右偏移 1 列 → 定位到 上一行的 C 列因此 C1:OFFSET(B,-1,1) 表示从 C1 到当前行上方一行的 C 列区域(即不包含当前行)同理,B1:OFFSET(B,-1,) 表示从 B1 到当前行上方一行的 B 列区域4 FILTER(C1:OFFSET(B,-1,1), B1:OFFSET(B,-1,) = B, 0)
作用:在当前行之前的所有行中,筛选出零件等于当前零件 B 的那些数量。
条件 B1:... = B:找出历史中同零件的行返回对应的 C 列数量值组成的数组若无匹配项,FILTER 返回错误,但因有第3参数 0,会返回 0(不过实际由外层 SUM 处理)5 SUM(FILTER(...))
作用:对筛选出的历史数量求和。
如果当前是该零件第一次出现,则 FILTER 结果为空或无匹配 → SUM 返回 0如果是第二次或之后出现,则返回此前所有同零件数量的总和6 DROP(..., 1)
作用:去掉 REDUCE 生成结果中的第一个元素(即初始空值 "" 对应的占位行)。
因为 REDUCE 从 "" 开始,VSTACK 第一次会把 "" 和第一个结果拼在一起 → 形成 {""; 0; 8; ...}DROP(..., 1) 删除首行,使结果从真正的第一个数值开始,对齐 D2 单元格整体逻辑总结:
该公式通过 REDUCE 逐行遍历零件列,对每个零件动态查看其上方所有行中同名零件的数量,并求和。首次出现时上方无同名数据,SUM=0;后续出现时自动累加历史值。最后用 DROP 去掉初始空行,得到与数据行数一致的累计结果列。
特点:逐行累积,使用 REDUCE 构建最终结果每次遇到新零件时,通过 FILTER 获取其历史数据并求和DROP(...,1) 去除初始值优点:适合需要逐行累积的应用场景结果自然形成动态数组缺点:代码较长,不易于初学者理解多次调用 FILTER,可能影响性能方法四:使用 LET + SEQUENCE + MAP(高级控制型) 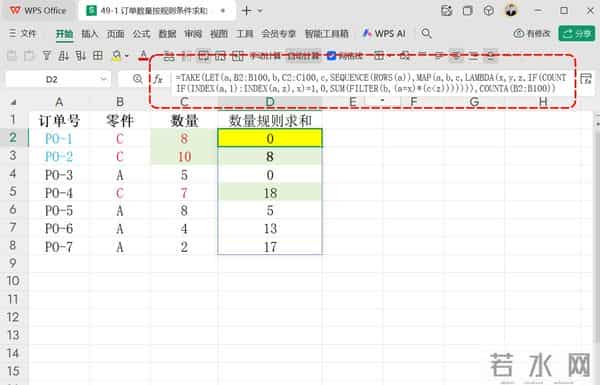
- =TAKE(LET(a,B2:B100,b,C2:C100,c,SEQUENCE(ROWS(a)),MAP(a,b,c,LAMBDA(x,y,z,IF(COUNTIF(INDEX(a,1):INDEX(a,z),x)=1,0,SUM(FILTER(b,(a=x)*(c
1 LET(a, B2:B100, b, C2:C100, c, SEQUENCE(ROWS(a)), ...)
作用:定义三个变量,提升公式可读性和复用性。
a = B2:B100 → 零件列(从第2行到第100行)b = C2:C100 → 数量列(对应零件的数量)c = SEQUENCE(ROWS(a)) → 生成序号数组 {1;2;3;…;99},表示每行在 a 中的相对位置(第1行为1,第2行为2,依此类推)2 MAP(a, b, c, LAMBDA(x, y, z, ... ))
作用:对 a、b、c 三个数组的每一组对应元素同时进行处理。
x = 当前行的零件(来自 a)y = 当前行的数量(来自 b)z = 当前行的序号(来自 c,即这是第几行数据)相当于“逐行遍历”,并能知道当前是第几行(z),便于定位历史范围3 INDEX(a, 1):INDEX(a, z)
作用:动态构造从第1行到当前行 z 的零件子区域。
INDEX(a,1) → a 的第1个元素(即 B2)INDEX(a,z) → a 的第 z 个元素(即当前行的零件)合起来等价于 B2 到当前行的零件范围(如第3行时,就是 B2:B4)4 COUNTIF(INDEX(a,1):INDEX(a,z), x) = 1
作用:判断当前零件 x 在“从开头到当前行”中是否为首次出现。
如果等于 1 → 是第一次 → 返回 0如果大于 1 → 已出现过 → 进入累计逻辑5 (a = x) * (c < z)
作用:构造一个布尔掩码,用于筛选“当前零件 x 且行号小于当前行”的所有行。
a = x → 所有等于当前零件的行(TRUE/FALSE)c < z → 所有在当前行之前的行(TRUE/FALSE)两者相乘(*)实现“AND”逻辑,结果为 1(TRUE)的位置即为符合条件的历史行6 FILTER(b, (a = x) * (c < z))
作用:从数量列 b 中,提取出同零件且在当前行之前的所有数量。
例如:当前是第5行(z=5),x="C",则只取前4行中零件为 "C" 的数量7 SUM(FILTER(...))
作用:对上述筛选出的历史数量求和,得到“此前累计值”。
若无历史记录(首次出现),FILTER 返回空,SUM 返回 0(但此情况已被前面的 IF 拦截)8 IF(COUNTIF(...) = 1, 0, SUM(...))
作用:综合判断并返回结果。
首次出现 → 返回 0非首次 → 返回历史累计和9 TAKE(..., COUNTA(B2:B100))
作用:截取最终结果的前 N 行,其中 N = 实际非空零件数。
因为 a 定义为 B2:B100(固定99行),但实际数据可能不足100行COUNTA(B2:B100) 统计非空单元格数量,确保结果只包含有效行,避免多余零或错误值特点:高度自定义,使用 SEQUENCE 和 MAP 提供灵活控制COUNTIF 判断是否为首行,是则返回 0SUM(FILTER(...)) 实现累计求和(仅包含之前的数据)优点:完全控制输出范围和顺序支持复杂逻辑扩展缺点:代码较复杂,理解难度较大需要较高的 Excel 函数掌握程度核心知识点总结编号
知识点
说明
1
FILTER 是前置筛选工具
必须先根据零件筛选出同类型的历史数据,才能进行累计计算
2
MAP 是逐行处理的核心函数
对每一行独立执行逻辑,适用于“按行判断并计算”的场景
3
OFFSET 动态获取历史区域
结合 B2:x 等动态引用,实现当前行以上所有数据的提取
4
SUM + TAKE 实现排除当前值
SUM(a) - TAKE(a, -1) 剔除当前行的数量,仅保留历史总和
5
LET 提升公式可读性
定义变量避免重复引用,尤其适用于复杂嵌套结构
6
DROP 用于删除指定位置的数据
如 DROP(..., 1) 删除初始空值,确保输出结果从第一行开始
实际应用建议 优先推荐使用方法一(MAP + FILTER):代码简洁、性能高,适合日常业务分析 若需兼容旧版 Excel,可用方法二(SUMIFS + COUNTIF):不依赖动态数组,但逻辑稍显冗长 对于大数据集或复杂逻辑,考虑方法四(SEQUENCE + MAP):灵活可控,适合高级用户 注意:所有方法均需保证数据连续且无空行,否则可能导致错误或结果偏差如需进一步拓展功能(如按人员分配、时间排序、状态标记等),可在该基础上继续构建模型。
小结口诀“筛选再累计,
MAP来搞定;
历史全取走,
当前减掉它;
LET定义好,
一行写完它。”
此操作是订单管理系统中常见的分组累计统计任务。掌握这些技巧,不仅能高效完成数据处理,还能迁移到其他业务场景(如库存预警、生产进度跟踪等),大幅提升自动化能力。
最终结论:
每个零件独立累计,首次出现返回 0,后续依次累加其历史数量,通过 MAP、FILTER、OFFSET 等函数组合实现精准控制。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





