vLLM-Omni 多模态AI服务框架
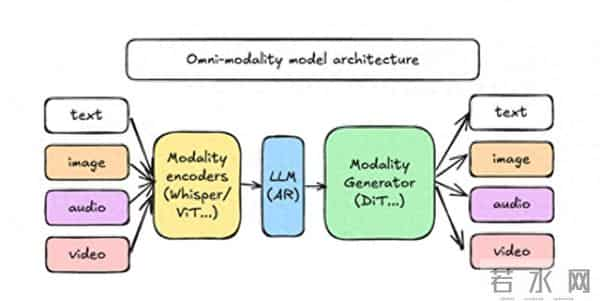
现代推理流程不再仅仅依赖于自回归 (AR) 语言模型。相反,它们结合了不同的模型类型——用于文本的 AR Transformer、用于图像和视频生成的扩散模型,以及用于音频和多模态理解的专用编码器。
这种转变需要一个能够高效处理文本、图像、音频、视频和扩散架构的服务引擎,而无需工程师在多个框架之间切换。
如今,这一切终于变得简单了。
隆重推出 vLLM-Omni——一个开源框架,它能提升 vLLM 在 Qwen-Omni 和 Qwen-Image 等全模态模型上的速度、易用性和成本效益。
如果您已经掌握了 vLLM 的使用方法,那么您自然也会使用 vLLM-Omni。
 1、vLLM-Omni 的重要性
1、vLLM-Omni 的重要性
传统的模型服务框架主要关注基于文本的自回归模型。而多模态系统则需要:
vLLM-Omni 将所有这些功能整合到一个统一的服务栈中。
主要亮点:
让我们一起完成安装、设置和实际多模态推理的执行。
系统要求:
注意:vLLM-Omni 不支持 Windows 系统。
2.1 使用 Python + uv 进行设置uv 是一个超快的 Python 环境管理器(可以理解为功能更强大的 virtualenv + pip)。
创建新环境:
uv venv --python 3.12 --seedsource .venv/bin/activate2.2 安装 vLLM(基础引擎)
vLLM-Omni 基于 vLLM v0.11.0 构建。
uv pip install vllm==0.11.0 --torch-backend=auto2.3 安装 vLLM-Omni
uv pip install vllm-omni
完成!
2.4 可选:从源代码构建(如果您想修改 vLLM-Omni) git clone vllm_omniuv pip install -e .
如果您还要修改 vLLM 本身:
git clone vllmgit checkout v0.11.0
设置 wheel 文件位置:
export VLLM_PRECOMPILED_WHEEL_LOCATION=
安装:
uv pip install --editable .
或者,如果 PyTorch 已安装:
python use_existing_torch.pyuv pip install -r requirements/build.txtuv pip install --no-build-isolation --editable .3、运行离线推理 (Qwen2.5-Omni)
该仓库包含可直接运行的离线推理示例。
3.1 运行多个提示首先,下载 seed_tts 数据集并提取提示:
/seedtts_testset.tarcp seedtts_testset/en/meta.lst examples/offline_inference/qwen2_5_omni/meta.lstpython3 examples/offline_inference/qwen2_5_omni/extract_prompts.py \ --input examples/offline_inference/qwen2_5_omni/meta.lst \ --output examples/offline_inference/qwen2_5_omni/top100.txt \ --topk 100tar -xf
导航到该文件夹:
cd examples/offline_inference/qwen2_5_omni
运行推理:
bash run_multiple_prompts.sh3.2 运行单个提示
cd examples/offline_inference/qwen2_5_omnibash run_single_prompt.sh3.3 使用本地媒体文件(图像、音频、视频)
end2end.py 脚本支持通过命令行参数进行多模态输入。
仅图像推理:
python end2end.py --query-type use_image --image-path /path/to/image.jpg
仅视频推理:
python end2end.py --query-type use_video --video-path /path/to/video.mp4
仅音频推理:
python end2end.py --query-type use_audio --audio-path /path/to/audio.wav
混合模态(音频 + 图像 + 视频):
python end2end.py --query-type mixed_modalities \ --video-path /path/to/video.mp4 \ --image-path /path/to/image.jpg \ --audio-path /path/to/audio.wav
从视频中提取音频:
python end2end.py --query-type use_audio_in_video --video-path /path/to/video.mp4
如果您不要传递任何文件,将使用默认资源。
4、以编程方式调用 vLLM-Omni以下是一个极其简单的多模态推理请求示例:
from vllm_omni import OmniEngineengine = OmniEngine(model="Qwen/Qwen2.5-Omni")result = engine.generate({ "query": "Describe the image.", "image": "/path/to/cat.png"})print(result["text"])
或者,对于混合输入:
result = engine.generate({ "query": "Summarize what is happening.", "video": "/path/video.mp4", "audio": "/path/audio.wav",})
librosa 后端错误?安装 ffmpeg:
sudo apt updatesudo apt install ffmpeg5、结束语
vLLM-Omni 代表了模型服务领域的一次重大飞跃:
如果您正在构建涉及文本、图像、音频或视频任意组合的 AI 应用,vLLM-Omni 是最简单、最强大的部署方式之一——开源、快速且已准备好投入生产。
原文链接:vLLM-Omni 多模态AI服务框架 - 汇智网
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





