从CNN到VIT:视觉Transformer的崛起
计算机视觉的主线技术,几乎都与卷积神经网络(Convolutional Neural Network, CNN)的演化密切相关。自1998年LeNet诞生到后来演化出的VGGNet,ResNet等。CNN在过去长达近二十年的时间里都是计算机视觉的绝对主角。
然而当视觉任务越来越复杂(例如语义分割,视频理解),CNN的局部感受野反而限制了它的效果,如果想要获取全局信息则需要多长层卷积,这也导致了参数爆炸,迁移能力差种种问题。
此时来自视觉NLP的Transformer以其全局自注意力机制(Self-Attention)闯入视觉领域,打破了CNN的局限。
1.传统CNN的缺点
尽管CNN通过滑动窗口提取图像特征很好地解决了参数量大,特征提取难的问题,但仍有许多不足。
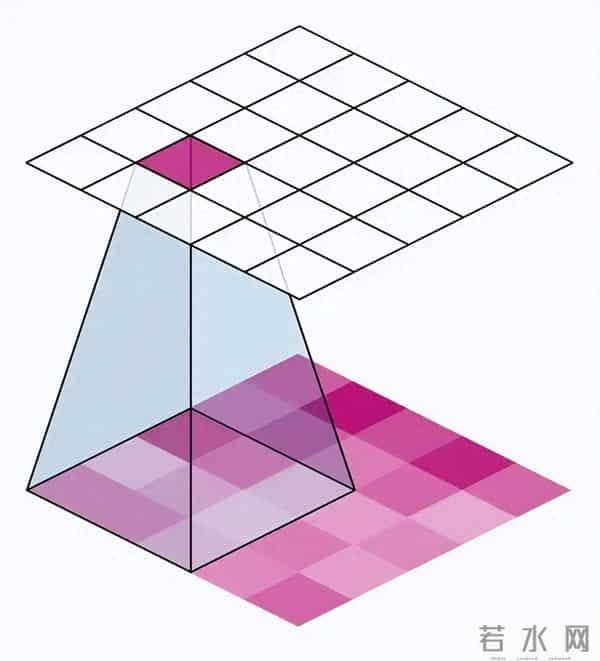 2.Transformer的思想:让模型看全局
2.Transformer的思想:让模型看全局
Transformer起源于NLP,在NLP领域,它通过自注意力机制实现了长距离依赖的建模。视觉领域同样也可以借用这一思想。
Transformer通过引入一种全局信息交互机制,让模型在任意两处特征之间建立联系
在数学形式上,自注意力机制可以表示为:
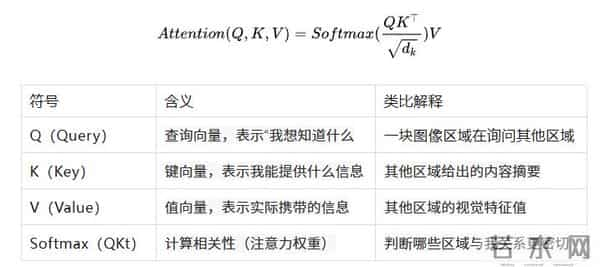
直观理解
假设模型正在分析一只“猫”的图片。
猫的“头部”区域(Query)会自动学习到它应该关注“身体”和“尾巴”区域(Key)
3.Transformer的工作流程
我们把一张图像分割成多个小块(patch),每个patch被映射为一个向量。再转换为一系列向量序列
同股票线性变换得到
Q=XWQ,K=XWK,V=XWV
A=softmax(dkQKT)
Y=AV 此时输出的Y包含了整张图中所有小块的加权信息
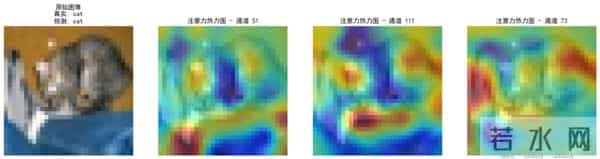
4.视觉任务中的直观效果在视觉Transformer(ViT)中,我们可以用“注意力热图”来可视化模型在看哪里:
5.Transformer的深远意义
1.全局信息建模 模型可以直接学习远近像素之间的相互作用,不再需要堆叠多层卷积网络来实现
2.动态自适应权重 每次输入不同图像,注意力权重都会重新计算 使得模型具有自适应性
3.获取信息不再依赖于空间卷积,不仅图像,文本视频都能以相同的方式处理,推动多模态的发展
总结
CNN擅长提取局部特征,而Transformer学会了理解全局关系。
这种“自注意力”的思想,不仅是一种算法机制,更是一种认知范式的转变: 模型不再被动地“卷积观察”,而是主动地“选择关注”。
这,就是Transformer让机器“看懂”世界的方式。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





