英伟达周末双炸!CUDA二十年最大更新,顺手屠榜AGI比赛
编辑:定慧 好困
【新智元导读】垄断全球的CUDA,迎来重大更新。
就在这个周末,英伟达干了两件大事。
不仅在硬件底层生态上扔下了一枚深水炸弹,还在软实力上秀了一把肌肉。
两件大事:
1. 软件生态的「地基」重塑:NVIDIA CUDA 13.1正式推出。这是CUDA平台诞生二十年来最大、最全面的一次更新。它引入了CUDA Tile编程模型,旨在屏蔽底层硬件细节,让开发者能更轻松地驾驭下一代GPU(如Blackwell)的恐怖性能。
2. 赢下AGI比赛:Kaggle ARC Prize 2025竞赛中,特级大师团队KGMoN以27.64%的分数夺得冠军。令人震惊的是,他们使用的并非千亿参数的巨型模型,而是一个仅4B的小模型变体,单次任务推理成本仅需20美分。
这周五,来自英伟达的Ivan Sorokin和Jean-Francois Puget,在Kaggle ARC Prize 2025的公开榜单上,以27.64%的分数夺得冠军。
这场比赛被业内许多人视为衡量人类向通用AGI进度的「实时晴雨表」。
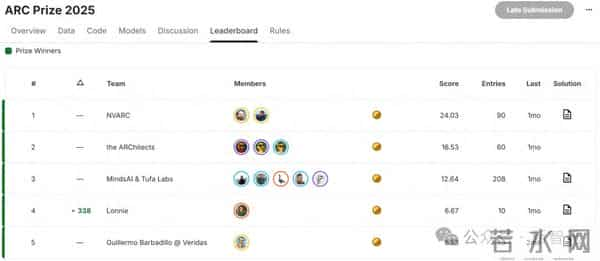
值得一提的是,他们的方案是在ARC-AGI-2基准测试背后的同一数据集上进行评估的。
NVARC一下子超过Claude Opus 4.5,并且成本很低(注意横轴每个任务消耗为对数坐标轴)!
与此同时,英伟达还推出了自CUDA平台诞生二十年以来最大、最全面的更新——NVIDIA CUDA 13.1。

拿下AGI「圣杯」
4B小模型碾压全场
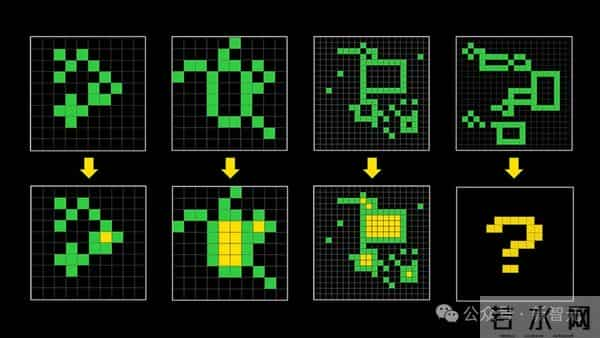
如今,ARC-AGI已经成为了观察AI通用推理真正进展的,最受关注的指标之一。
跟典型的机器学习基准不同,ARC-AGI的任务没法靠堆规模、死记硬背或者抓取模式来搞定。
它是AI界公认的「智商测试」,由Keras之父Franois Chollet提出,专门测试AI面对陌生问题的举一反三能力,而不仅仅是死记硬背。

核心秘诀:320万合成数据的「暴力美学」
NVARC方案最震撼的地方,在于他们构建了一个极其复杂的合成数据生成流水线。
他们没有依赖原本稀缺的几百个训练题,而是自己造了320万个!
他们的逻辑很简单:如果AI没见过类似的推理题,那就生成无穷无尽的类似题目让它看个够。
思路:合成数据、测试时训练(Test-timetraining)以及严谨的工程化。
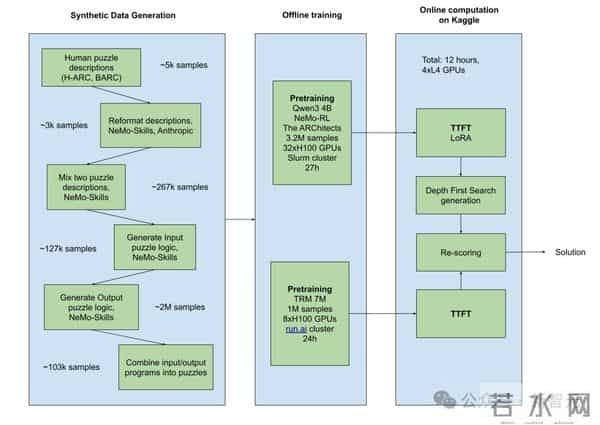

数据生成的「四步走」战略
他们使用了一个120B参数的开源大模型(gpt-oss-120b),通过NeMo-Skills框架搭建了如下流水线:

最终,他们构建了一个包含320万个增强样本的超级数据集!

模型选择:小模型,大智慧
有了海量数据,用什么模型来学呢?
NVARC并没有使用乃至微调那种几千亿参数的巨型模型,而是选择了Qwen3(4B参数)。

为什么选小模型?
1. 速度快:ARC竞赛有严格的时间限制,小模型推理飞快。
2. 效果好:在特定领域(Coding/Reasoning)的海量高质量合成数据喂养下,4B模型的表现完全可以吊打未经微调的巨型模型。
他们使用NeMoRL框架和Megatron后端进行了高效的全量微调(SFT),让模型学会了「看图写代码」的能力。

推理时的魔法:TTT与DFS
模型训练好了,在考场上(推理阶段)怎么发挥最大威力?
NVARC用了两个大招:
对于测试集中的每一个新谜题,他们不会直接预测答案,而是先利用该谜题给出的几个示例,快速用LoRA技术微调一下模型。
让模型在做题前,先「适应」一下这个题目的独特风格。

模型生成的不仅仅是答案,而是生成答案的Python代码。这意味着,他们可以运行这些代码来验证结果是否符合示例。
通过Batch DFS算法,他们批量生成多种可能的代码路径,一旦某段代码完美解决了所有示例,大概率也能解决测试题。

在比赛的最后10天,NVARC团队还尝试引入了ARC社区非常火的TRM(微型递归模型)。
虽然由于时间仓促,TRM并没有成为得分的主力(主要还是靠Qwen3+合成数据),但这种将「递归推理」与「大模型直觉」结合的思路,非常有启发性。
在最终的集成方案中,TRM也为分数的提升贡献了微薄但宝贵的力量。
NVARC的胜利再次证明了Scaling Law在推理任务上的有效性,但这次Scaling的对象不是模型参数量,而是高质量的合成推理数据。
通往AGI的路上,也许不需要更复杂的架构,只需要更聪明的「造题」方法。
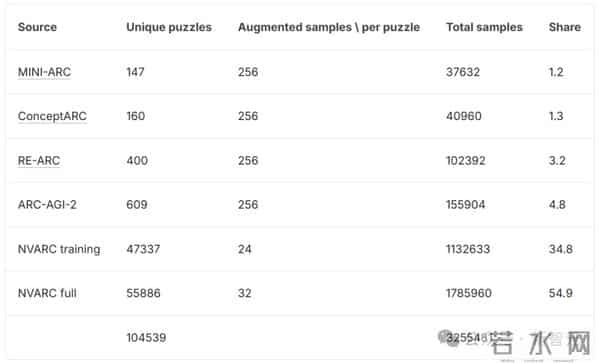
为此,团队除了合成数据,还用了一些真实的谜题数据集。
最终数据集包含了320万个增强样本,每个样本包含多达7对输入/输出。
在后训练(post-training)阶段,团队基于NeMoRL框架,并用Megatron后端进行了监督微调(SFT),这样能高效利用多节点H100GPU的显存和计算资源。
期间,为了全量微调4B模型,团队用了4个8xH100节点跑了27个小时。
在测试时,团队对每个谜题独立进行了LoRA微调(test-timefine-tuning),参数设为r=256和alpha=32。
期间,既要去掉梯度检查点,也要去掉4-bit量化,并且微调要用bfloat16精度去跑。
除了这些,团队还配合Unsloth框架使用了FlashAttention2。

开源项目:
技术报告:
团队在ARChitects方法中做的主要优化,是在解码阶段实现了深度优先搜索(DFS)算法的批处理(batch)。
并且,还使用了额外的增强(augmentations)来对DFS阶段的候选结果进行重打分。
团队在这里做了一点小改动。
也就是,对每个候选解只用了8次增强,但确保对每个候选解使用完全相同的增强。
如此一来,不同解法的分数更有可比性。
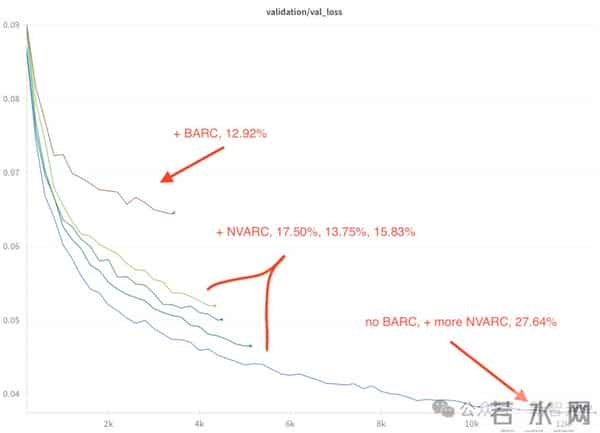
比赛期间,团队在不同比例的合成数据上微调了模型。
从下图中可以看到,在预训练阶段增加更多数据对损失函数的影响。
最好的模型在比赛期间拿到了27.64%的分数。

20年最大更新
CUDA 13.1彻底重构

CUDA Tile编程
为了帮助开发者为当前和未来的GPU构建软件,CUDA 13.1重磅推出了CUDA Tile。
基于此,开发者可以直接在SIMT之上的一层编写GPU Kernel(核函数)。
在SIMT编程中,开发者需要通过划分数据和定义每个线程的执行路径来指定Kernel。而通过CUDA Tile,则可以将代码提升一个层级,指定为Tile数据块。
开发者只需指定要在这些Tile上执行的数学运算,编译器和运行时会自动确定将工作分发到各个线程的最佳方式。
不仅如此,由于Tile模型屏蔽了使用Tensor Core等专用硬件的细节,因此开发者现在写的Tile代码将直接兼容未来的GPU架构。
除此之外,CUDA13.1还发布了两个用于Tile编程的组件:

CUDA软件更新
Green Context现已向运行时API开放CUDA中的Green Context(绿色上下文)是传统CUDA Context的轻量级替代方案,目的是在为开发者提供一种在GPU上进行更细粒度空间分区和资源预置的机制。
Green Context使开发者能够定义和管理GPU资源(主要是流多处理器,即SM)的独特分区,并将一组特定的SM专用给某个特定的Context。
然后,开发者可以启动CUDA Kernel,并管理仅在这个Green Context预置的资源内运行的流(Stream)。
CUDA13.1还引入了一个更可定制的split() API。
开发者可以构建以前需要多次API调用才能实现的SM分区,并且能够配置工作队列以最大限度地减少提交到不同Green Context的工作之间的虚假依赖。
CUDA多进程服务(MPS)更新CUDA13.1为多进程服务(MPS)带来了新特性和功能,其中的一些亮点包括:
内存局部性优化分区(MLOPart)是部分Blackwell(计算能力10.0和10.3)及更新GPU上的一项功能。开发者可以创建专门用于提高内存局部性的专用CUDA设备。
在受支持的GPU上使用MLOPart时,每个分区都显示为一个独立的CUDA设备,具有关联的计算和内存资源。
作为MPS中当前动态执行资源预置的替代方案,静态流多处理器(SM)分区是Ampere架构(计算能力8.0)及更新GPU的一项功能,它提供了一种为MPS客户端创建独占SM分区的方法。
这个模式的主要目的是提供确定性的资源分配并改善MPS客户端之间的隔离,可以通过使用-S或--static-partitioning标志启动MPS控制守护进程来启用。

开发者工具
CUDA Tile Kernel分析NVIDIA Nsight Compute 2025.4增加了对分析CUDA Tile Kernel的支持。
更新包括:
此外,还增加了对分析设备启动的Graph中的CUDA Graph节点的支持,以及源页面导航的改进,为编译器生成和用户生成的标签提供了可点击的链接。
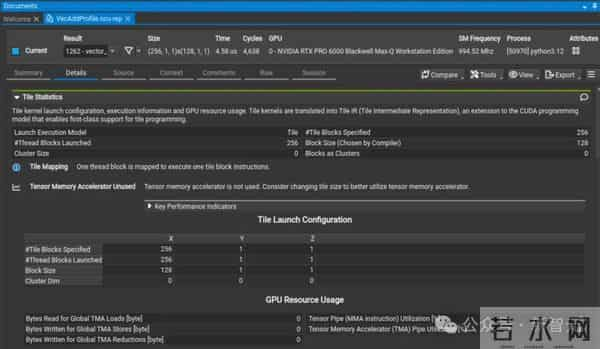
Nsight Compute分析概况,突出显示了分析输出的Tile Statistics部分
编译时修补NVIDIA Compute Sanitizer 2025.4通过-fdevice-sanitize=memcheck编译器标志增加了对CUDA编译器(NVCC)编译时修补的支持。这种修补增强了内存错误检测并提高了Compute Sanitizer的性能。
编译时插桩将错误检测直接集成到NVCC中,以实现更快的运行速度,同时通过高级的基址和边界分析捕获更隐蔽的内存问题,例如相邻分配之间的非法访问。
这意味着用户可以在不牺牲速度的情况下调试内存问题,运行更多测试并保持生产力。
要使用此新功能,请使用如下NVCC标志编译代码:
nvcc-fdevice-sanitize=memcheck -o myapp myapp.cu
然后使用memcheck工具通过compute-sanitizer运行你的应用程序:
compute-sanitizer--toolmemcheck myappNVIDIA Nsight Systems
NVIDIA Nsight Systems 2025.6.1与CUDA Toolkit 13.1同步发布,其中包括了多个全新的追踪功能:

数学库
核心CUDA Toolkit数学库的新功能包括:
一个新的带有Grouped GEMM的实验性API,支持Blackwell GPU上的FP8和BF16/FP16。
针对上述数据类型的Grouped GEMM,提供了一种无需主机同步的实现,在MoE用例中比多流GEMM实现速度提升高达4倍。
一个新的稀疏矩阵向量乘法(SpMVOp)API,与CsrMV API相比性能有所提高。
此API支持CSR格式、32位索引、双精度和用户定义的epilogue(后处理)。
一组cuFFT device API,提供用于在C++头文件中查询或生成设备函数代码和数据库元数据的主机函数。
它专为cuFFTDx库设计,通过查询cuFFT来促进cuFFTDx代码块的生成,这些代码块可以与cuFFTDx应用程序链接来提高性能。
cuBLAS Blackwell性能CUDA Toolkit 12.9在Blackwell上引入了块缩放(block-scaled)的FP4和FP8 matmul。
CUDA13.1增加了对这些数据类型和BF16的性能支持。
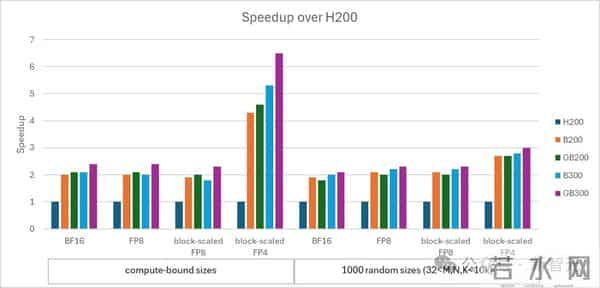
在不同数值精度下,Blackwell GPU相对于H200的加速比
cuSOLVER Blackwell性能CUDA13.1继续改进用于特征值分解的批处理SYEVD和GEEV API,提供了性能增强。
批处理SYEV(cusolverDnXsyevBatched)是cuSOLVER SYEV例程的统一批处理版本,用于计算对称/厄米矩阵的特征值和特征向量,非常适合并行求解许多小矩阵。
在批量大小为5000(24-256行)的测试中,与L40S相比,RTX Pro 6000实现了约2倍的加速.
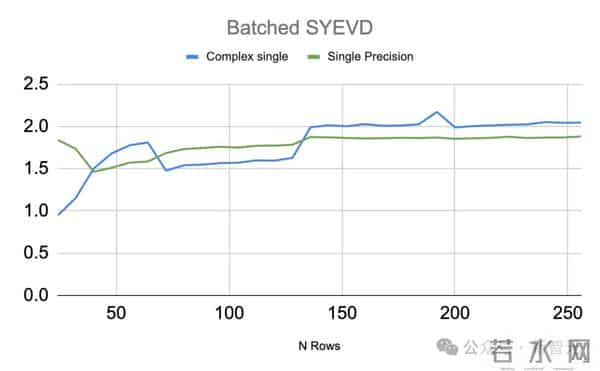
cusolverDnXgeev(GEEV)是一种混合CPU/GPU算法,用于计算一般(非对称)稠密矩阵的特征值和特征向量。
在矩阵大小从1024到32768的测试中,RTX PRO 6000相对于L40S实现了最大超1.5倍的性能。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。



