告别算力焦虑!2比特量化媲美FP16,北大新框架颠覆模型压缩
在阅读此文之前,辛苦您点击一下“关注”,既方便您进行讨论和分享,又能给您带来不一样的参与感,感谢您的支持!
手机想跑个70亿参数的大模型,以前想都不敢想。
就拿常见的7B模型来说,用FP16精度得占14GB存储空间,普通手机哪有这么大地方。
更别说汽车、物联网这些边缘设备,算力和存储更是紧张。
 模型压缩技术早就有了,但超低比特量化一直是个老大难
模型压缩技术早就有了,但超低比特量化一直是个老大难
1-2比特压缩出来的模型,性能掉得厉害,困惑度噌噌往上涨。
要么就得重新训练,要么大量微调,成本高得吓人,一般团队玩不起。
最近北大团队整了个新活,叫Fairy2i框架。
不用重新训练,直接拿预训练好的实数模型就能压缩到2比特,性能还能跟FP16掰掰手腕。
这可不是小打小闹,对边缘设备部署来说,简直是打开了新世界的大门。
咱们先说说这个模型压缩到底难在哪儿。
想把模型变小,又不想性能下降太多,这本身就是个矛盾。
以前搞1比特二值化,存储是小了,但精度也跟着崩了。
4比特量化稍微好点,可还是不够轻巧,边缘设备照样扛不住。
更麻烦的是重新训练这事儿,有些复数域模型,比如之前的iFairy,得从头开始训,几千个GPU小时砸进去,一般人哪耗得起。
本来想靠重新训练解决精度问题,后来发现成本太高,根本普及不了。
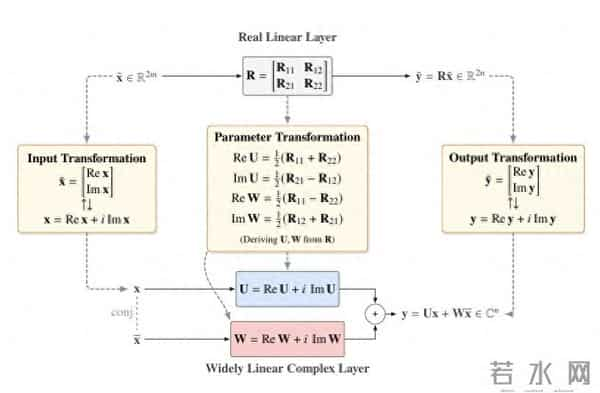
Fairy2i框架玩了个数学魔术,叫广义线性表示。
简单说,就是把偶数维的实数线性层,无损转换成复数形式。
参数规模不变,推理结果也一样,直接复用LLaMA这些现成的预训练权重。
这就相当于给模型换了身衣服,里子没变,外面却更合身了。
不用从零开始搭复数模型,省去了海量的算力消耗。
有了这个"零误差起点",后面的量化操作才能站得住脚。
光换衣服还不够,还得学会高效编码。
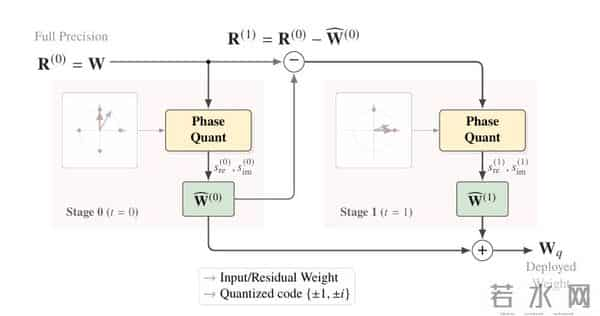
Fairy2i用了相位感知量化,在复数域搞了个码本,用单位圆上的四个点{±1,±i}当基本单位。
跟实数域的二值或三值编码比,信息密度一下子提高了50%。
这么一来,矩阵乘法就变成了简单的加减和数据交换,浮点乘法那套复杂操作直接拜拜。
这种操作就像把乘法题换成了加减法,计算速度能不快吗?误差问题怎么解决,Fairy2i搞了个递归残差量化。
分阶段把误差一点点消除掉,两个阶段就能达到2比特效果。
把权重拆成几个低比特项相加,噪声自然就小多了。
最妙的是,这些残差计算可以并行处理,精度上去了,推理延迟却没怎么增加。
本来以为多阶段操作会变慢,结果发现并行处理把时间抢回来了,这波操作确实秀。
说了这么多原理,实际效果到底咋样?团队拿LLaMA-27B模型做了测试,在C4数据集上的困惑度是7.85。

对比一下,GPTQ-2bit的困惑度差不多9.5,FP16全精度是6.63。
零样本任务平均准确率62.00%,跟全精度的64.72%比,就差了2.72个百分点。
2比特能做到这个程度,已经超出不少人的预期了。
存储方面更不用说,从14GB直接干到1.75GB,压缩了8倍。
现在手机随便腾出点空间就能装下7B模型,以前想都不敢想。
搞不清以前那些压缩方法为啥没做到这么极致。
推理的时候不用乘法,全是基础算术操作,手机NPU就能轻松拿捏。
以前觉得手机跑大模型是天方夜谭,现在看来,也就是个时间问题。
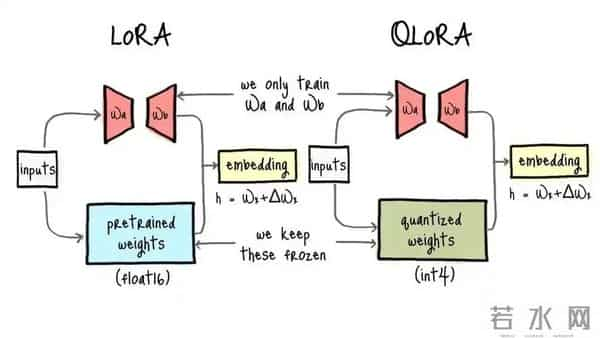
跟其他技术比,Fairy2i最大的优势就是不用重新训练。
iFairy得从头训复数模型,AWQ要微调激活值,Fairy2i直接拿预训练模型就能用,适配性强多了。
INT8量化精度接近但压缩不够,二值化压缩够了但精度不行。
Fairy2i算是找到个平衡点,精度和效率两手抓,这才是真本事。
这项技术落地后,边缘设备AI算是迎来了春天。
手机离线语音助手响应更快,车载系统处理数据不用等云端,工业传感器实时分析也成了可能。
IDC报告说AI算力需求每年涨300%,低比特量化能减少一半以上的计算资源消耗。
成本降下来了,普通用户才能真正享受到AI的便利。

复数域这块还有不少潜力可挖,团队说要是用300亿以上的token训练,说不定低比特模型能反过来超过全精度。
数学的力量有时候就是这么神奇,信号处理领域在复数域玩了这么多年,经验完全可以搬到AI这边来。
以后图像、语音这些多模态模型,说不定也能用低比特量化搞轻量化。

这次北大团队和九章云极、大湾区大学合作,算是产学研结合的典范。
算法创新加工程落地,技术才能真正走进生活。
代码和模型都开源了,大家一起完善,标准化进程肯定能加快。
当然,挑战还是有的。
怎么把递归阶段增加到T>2,进一步逼近全精度?多模态模型能不能用这套方法?这些问题都等着大家去探索。

总的来说,Fairy2i靠广义线性表示、相位感知量化和递归残差量化这三招,把2比特模型的性能拉到了接近FP16的水平,还不用重新训练。
在LLaMA-27B模型上的表现已经证明,这个方案确实能兼顾精度和效率。
边缘设备跑大模型不再是口号,而是看得见摸得着的现实。

AI从云端走向边缘,这步棋算是走活了。
算力成本降了,隐私保护好了,智能普惠离我们又近了一步。
说不定过不了多久,咱们的手机里都能揣着个"小大脑",随时待命。
【免责声明】:本文创作宗旨是传播正能量,杜绝任何低俗或违规内容。如涉及版权或者人物侵权问题,请私信及时联系我们(评论区有时看不到),我们将第一时间进行处理!如有事件存疑部分,联系后即刻删除或作出更改。

声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





