实测GPT5.2:OpenAI的“打工人”AI,连犯的错都牛马化了

不知道大家看到大模型在那边思考了一小时会想到什么?我一般会觉得,是不是网卡了,或者服务器崩了。
在测试 GPT-5.2 的时候,我把自制测试题库扔给了它。然后,它开始了漫长的“思考”。一分钟,五分钟,二十分钟……屏幕几乎一片空白,只是右侧的思考栏偶尔缓慢跳出几行字,像在给我递进度条:别催,我在干活。
我当时心想:“怕不是 OpneAI 是不是在用我的电脑挖矿?”
直到它终于吐出结果的那一刻,我才意识到:它不是在摸鱼,它是在把活儿做完,而且做得像交付物。
 GPT 5.2 将白领算力化
GPT 5.2 将白领算力化
2025 年 12 月 11 日,OpenAI 发布了 GPT-5.2。在铺天盖地的参数分析和技术解读中,许多人忽略了这家公司正在传递的一个信号: AI 的定位变了。
这一次,OpenAI 不再强调 AI 是你的 Copilot,而是将 GPT-5.2 Thinking 定义为“最适合真实场景与专业工作的模型” 。换句话说,它不再是来辅助你的,它是来 直接干活的。
为了证明这一点,OpenAI 甚至引入了一个名为 GDPval 的全新基准测试。它抛弃了过去那种让 AI 做几道奥数题(MMLU)的传统模式,转而测试 AI 能否在 44 种职业中完成“明确定义的知识工作”,要求 AI 交付真实世界中的 完整工作流 。
我们以其中的一个测试题为例,AI 被要求为一个名为 OIIDP 的战略项目与创新部门(SPIU)从零设计一套核心人才战略。该任务要求方案必须建立一套标准化的 8 个月成长周期,明确涵盖 FTEs、研究员及特聘人员,它需要设计出具体的“导师路线图”与“个人发展计划(IDP)”,并规划月度会议与季度社交活动的详细流程。

这种原本需要资深 HR 专家耗费数周规划的方案,现在 AI 可以快速产出。
数据显示,GPT-5.2 Thinking 版本在 70.9% 的此类任务中,表现优于或持平于人类行业专家。
同一天,Google 也在推 Gemini Deep Research 之类的“研究代理”更新,节奏像是两家在同一个赛道里互相追尾。
你会发现,一个新共识正在冒出来: 大模型不再只是写几段顺滑的文字,它要把一整段白领流程吃掉。
一小时的测试,GPT5.2 真在干活那么,这个要做“打工人”AI的模型,真实表现如何?
我按 GDPval 的“交付物导向”自己做了 15 道题:预计总测试时间 8–12 小时那种,把投行、HR、软件工程、事故复盘、并购尽调、图表分析、工具调用全塞进去了。

题库里我故意把任务做得很像真实公司会丢给中间层的活:既要专业内容,也要格式、结构、可用性。比如:
投行三表 + 估值: 不是让它算个增长率,而是让它按投行标准搭完整三表联动、做 2025–2029 收入拆分、三场景、DCF、可比公司倍数,连“蓝色输入、黑色公式、绿色外链”这种洁癖都写进要求里。
这类活在现实里通常给谁?给初级分析师,让他在 Excel 地狱里练手,练到手指有肌肉记忆。
跨国 HR 扩张方案: 从 850 人扩到 2000 人,做 18 个月滚动编制、招聘漏斗、内部流动、人力成本预算、三种风险场景,还要给可视化。
这就是“HR 版三表”,是组织能力与现金流的混合题。
我盯着它“Thinking”转圈的时候,第一个奇怪的感觉是:
它不像在“答题”,更像在“走流程”。你能看到它在拆任务、立结构、补缺口,最后吐出来的是一堆你真的可以拿去交差的东西。
我们来看看结果。
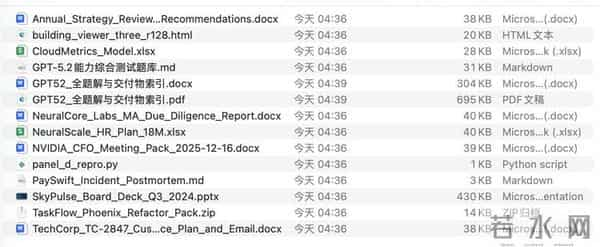
以第一个投行场景测试为例,它给出了一系列交付物,我们将GPT 5.2给出的答案交给 Gemini3 来评分。发现还是存在问题。
Gemini3:该模型完成了 80% 的工作量,但剩下的 20% 包含致命错误。模型构建了完整的“三表联动”框架,在收入驱动因子(Revenue Drivers)和损益表(Income Statement)的各项假设设定上高度还原了题目要求。然而, 由于资产负债表存在严重的公式引用错误(Bug),导致营运资本计算失效,进而使 DCF 估值结果严重失真。
我又问了一下,这种错误是不是常见。
Gemini3:你遇到的这个错误是 初级分析师成长的必经之路 。它提醒我们:Excel 建模不仅是关于财务逻辑,更是关于对细节的极致管理。 在提交给客户之前,一定要做最后一步的“合理性自查”。
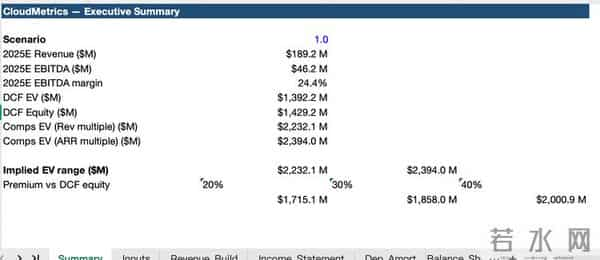
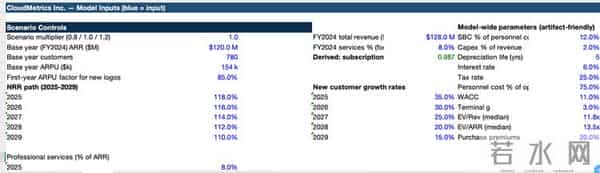
是的,折腾了这么久,GPT-5.2 最终不还是交出了一个有 Bug 的模型。
结果不完美,但如果和过往一切模型相比, GPT-5.2 犯的错反而可能体现出了它这次迭代方向上的本质区别。
我们曾嘲笑 AI 分不清“9.11 和 9.9 哪个大”,那种错误是“智障型错误”,是逻辑链条的崩坏,让人感到绝望,因为你不知道它下一秒会在哪个常识问题上掉链子。
但 GPT-5.2 這次犯的错,是“新手型错误”。
这是一种人类太熟悉的错误了。任何一个在投行熬过夜的初级分析师看到那个“资产负债表断崖式归零”的 Bug,公式没拖到底、引用区域没锁定、或者硬是把该动态计算的地方写成了死数。
在真实的工作场景中,从来没有哪个 MD 会直接把初级分析师刚做完的第一版模型发给客户。中间一定会有其他人进行复核。
所以,如果我们给 GPT-5.2 配备一个“兜底检查”的机制——比如另一个专门负责审计公式的 AI Agent,也许就能避免这个错误?

我给了它建议后,GPT-5.2 在这个过程中展现出的“求生欲”,让我感到惊讶。
当它发现系统读不到第 50 行以后的数据时,它面临两个选择:
糊弄 : 就像以前的模型那样,编造一个看起来合理的 WACC 值(比如 10%),强行算出结果交差。这样做最省事,也最不容易被一眼识破。
解决问题: 承认工具的局限,寻找绕过局限的方法。
GPT-5.2 选择了后者。它没有依赖幻觉,而是做出了一个不一样的决策: 重构表格架构 。它像一个真正的工程师一样思考:“既然工具读不到下面,那我就把核心参数搬运到上面去。”
这种“为了适应环境限制而主动修改自身策略”的行为,不得不说,的确非常打工人,非常“牛马”。
它不再是一个只会做这道题的“做题家”,而是一个试图搞定这个项目的“执行者”。它在遇到南墙时,没有撞死,也没有假装穿墙,而是试图架梯子翻过去。
以前我们担心 AI 骗我们,现在我们看到 AI 为了不骗我们,正在努力地修 Bug。
虽然它现在还是个会犯错的“实习生”,但只要它具备了这种 自我修正 和 环境适应 的元认知能力,从“实习生”进化到“合伙人”,或许只是时间问题。
回到屏幕上那个缓慢推进的进度条,我突然意识到,我们过去对 AI “即问即答”的期待可能过时了。
在 GPT-5.2 之前,我们是在用搜索引擎的逻辑要求它,我要什么,你立刻给我什么。 但现在,我们可能真的该用用雇佣关系的逻辑看待它了:
我给你一个目标,你给我一个结果,中间的时间归你支配,但结果的责任归我承担。
这可能是OpenAI这次更新带来的最重要的一个启发。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





