谷歌推出 Titans 架构,为长期记忆处理器 (LLM) 提供长期记忆功能

人工智能模型如何在超长对话中保持连贯性?这一困扰业界多年的技术难题正在被谷歌的最新研究成果打破。谷歌研究团队发布的两篇论文提出了Titans架构和MIRAS理论框架,使AI模型能够在推理过程中实时更新记忆,处理超过200万词元的上下文信息——这一能力相当于同时记住约15本长篇小说的全部内容。
传统Transformer模型依赖注意力机制处理信息,但其计算成本随序列长度呈平方级增长,这使得处理完整文档、基因序列或长篇对话等超长上下文在实践中几乎不可行。循环神经网络和状态空间模型虽然提供了替代方案,但它们将上下文压缩为固定大小的表示,在处理极长序列时会丢失关键信息。谷歌的创新之处在于引入"测试时记忆"概念,使模型能够在运行时主动更新参数以保持长期记忆,而无需离线重新训练。
仿生机制的技术实现
Titans架构的核心是神经长期记忆模块,其本质是一个深度多层感知器网络。与传统循环神经网络使用固定大小向量存储记忆不同,这种设计显著提升了模型的表达能力,使其能够在不丢失关键信息的前提下概括海量数据。

最关键的创新来自"意外指标"机制,这一设计灵感源自人类心理学:我们倾向于忘记日常琐事,却能清晰记住出乎意料的事件。Titans利用内部误差信号检测新信息与当前记忆的差异程度。当遇到符合预期的常规信息时,模型跳过永久存储步骤以节省计算资源;当检测到异常数据点或意外信息时,模型优先将其写入长期记忆。
谷歌通过两个关键机制强化了这一过程。动量机制确保模型能捕获相关的后续信息,即使单个词元本身并不令人意外——就像人类在理解一个复杂事件时,会将前后关联的细节串联起来。自适应权重衰减则充当"遗忘门"的角色,在处理极长序列时管理有限的内存容量,类似于人脑选择性遗忘不重要信息的机制。
MIRAS框架为这些方法提供了理论支撑。它不再将不同AI架构视为独立系统,而是将Transformer、循环神经网络和状态空间模型统一在同一框架下,通过四个关键维度定义序列模型:记忆架构、注意力偏向、记忆保持机制和记忆算法。重要的是,MIRAS突破了几乎所有现有序列模型依赖的均方误差范式,为架构创新开辟了更广阔的设计空间。
利用MIRAS框架,谷歌派生出三种无需注意力机制的模型变体。YAAD对异常值具有更强的鲁棒性,适用于噪声较多的数据环境。MONETA探索复杂的数学惩罚函数以实现更稳定的长期记忆,使用超越简单二范数回归的损失函数。MEMORA通过限制记忆模块像严格概率映射一样运作,实现了最佳的记忆稳定性。这三种变体展示了MIRAS框架在平衡模型灵敏度、噪声抑制和记忆持久性方面的灵活性。
性能突破与实际应用
谷歌的测试结果在多个基准上展现了显著优势。在C4和WikiText等标准语言建模数据集上,Titans及MIRAS变体的准确率持续超越Transformer加强版、Mamba-2和Gated DeltaNet等领先架构。更令人瞩目的是其在超长上下文场景下的表现。
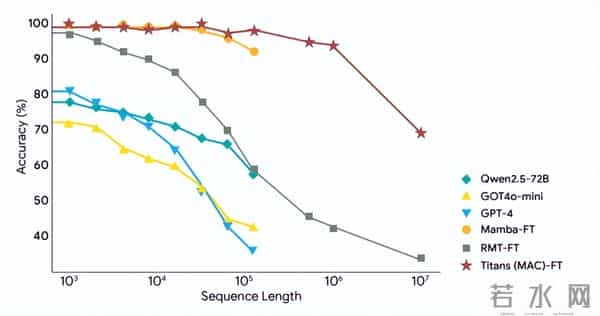
BABILong基准测试要求模型对分布在超长文档中的事实进行推理,Titans在此测试中的表现优于所有基线模型,包括参数量远超其数倍的GPT-4。该架构已被验证能够有效处理超过200万词元的上下文窗口,而传统Transformer模型在处理数万词元时就已开始出现性能退化。
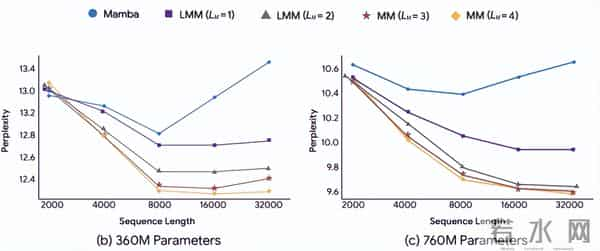
消融研究揭示了记忆架构深度的重要性——更深的记忆模块持续带来更好的性能,并且随着序列长度显著增加,性能保持良好的扩展性。这证明了神经长期记忆模块相比简单向量表示的优越性。
Titans的优势不仅体现在文本处理领域。谷歌已成功将该架构应用于基因组建模和时间序列预测,验证了其通用性。在基因组序列分析中,模型需要从数百万碱基对中识别模式;在金融时间序列预测中,需要从海量历史数据中提取长期趋势——这些任务都要求模型具备处理超长序列的能力。
更重要的是,Titans保持了高效的可并行化训练和快速的线性推理速度。测试时训练机制虽然在推理过程中更新参数,但其计算开销远低于扩展注意力窗口的代价,使其适用于实际生产部署。
架构演进的深层意义
Titans和MIRAS的推出标志着序列建模领域的范式转变。从2017年"注意力即一切"论文奠定Transformer基础以来,该架构主导了自然语言处理领域。但其固有的计算瓶颈始终限制着长上下文应用的发展。Titans通过将循环神经网络的效率与Transformer级别的表达能力相结合,提供了一条新的技术路径。
对于需要长时间对话管理、文档级理解或持续学习能力的应用场景,Titans架构展现出巨大潜力。客服机器人可以记住数月前的对话细节,法律AI助手可以完整理解数百页合同条款,医疗诊断系统可以追踪患者多年的病史记录——这些应用都需要超越当前模型的长期记忆能力。
业界专家认为,大型语言模型缺乏长期记忆是其规模化部署的最大障碍之一。每次交互基本从零开始,无法在持续对话中积累知识和上下文理解。Titans的测试时训练机制使模型能够随着数据流输入主动学习和更新核心知识,而不是将所有信息压缩成静态状态。这种动态记忆更新能力,使AI系统向更接近人类认知方式的方向迈进了一步。
当然,从研究原型到大规模商业应用仍有距离。模型在极端场景下的稳定性、记忆更新的可控性、与现有系统的集成难度等问题还需要在实践中验证。但谷歌的这项研究无疑为AI发展开辟了新方向,也为解决长期困扰业界的记忆难题提供了可行方案。随着技术的成熟和优化,能够真正"记住"的AI系统或许将重新定义人机交互的可能性。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





