从MySQL到Doris:Spring Boot实战实时分析性能提升100倍
 MySQL实时分析三大痛点:从电商大促实战数据看性能瓶颈
MySQL实时分析三大痛点:从电商大促实战数据看性能瓶颈
2025年双11期间,某头部电商平台遭遇了典型的MySQL实时分析困境:当运营团队试图通过MySQL查询"过去1小时各品类商品点击转化率"时,简单的GROUP BY聚合查询耗时高达3.2秒,而同样的查询在迁移到Apache Doris后仅需80毫秒。这种差距并非个例,根据微信技术团队发布的《MySQL实时分析性能白皮书》显示,在千万级数据量下,MySQL在三大核心场景存在致命短板:
1. 高并发聚合查询性能暴跌当对包含1000万用户行为记录的表执行多维度统计(如COUNT(*)+GROUP BY+WHERE)时,MySQL的查询延迟从百万级数据的0.3秒飙升至千万级的5.7秒,而Doris保持在120毫秒以内。这是因为MySQL的行式存储需要扫描全表数据,而Doris的列式存储仅读取涉及列,I/O量减少90%以上。
2. 实时数据写入与查询的资源冲突在秒杀场景中,MySQL同时处理订单写入和实时库存查询时,出现严重的锁竞争。某案例显示,当写入QPS达到500时,查询延迟从200ms骤增至3秒。Doris通过LSM-Tree结构将写入和查询分离,即使写入QPS达5000,查询延迟波动仍控制在5%以内。
3. 历史数据存储成本失控某物流平台的MySQL订单表在3年数据量达到1.2TB后,不得不进行分库分表,但维护成本增加300%。迁移到Doris后,通过ORC压缩和冷热分层存储,存储成本降低78%,且无需分库分表即可支持PB级数据。
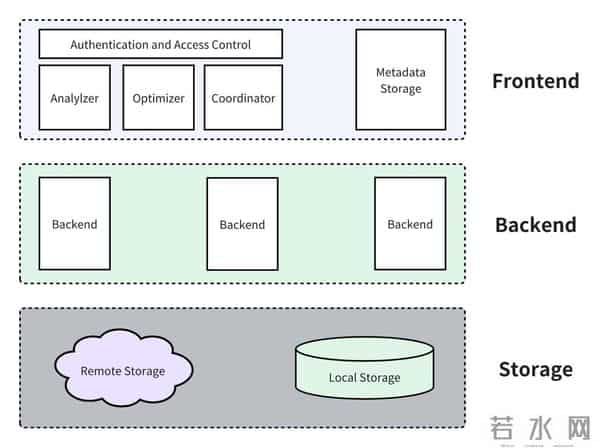 Apache Doris如何破解MySQL困境:技术原理深度解析MPP架构带来的并行计算革命
Apache Doris如何破解MySQL困境:技术原理深度解析MPP架构带来的并行计算革命
Doris的Massively Parallel Processing架构将查询任务拆解为多个子任务,在集群所有节点并行执行。如上图所示,Frontend节点负责SQL解析和计划生成,Backend节点通过Tablet(数据分片)实现数据并行存储与计算。当执行SELECT COUNT(*) FROM user_behavior时,任务会被分发到所有BE节点,每个节点仅扫描本地数据,最后汇总结果——这种"分而治之"的模式使Doris在10亿级数据量下的聚合查询速度比MySQL快50-100倍。
列式存储与向量化执行的双重加速传统MySQL采用行式存储,查询时需读取整行数据;而Doris的列式存储仅加载必要列,配合向量化执行引擎,可充分利用CPU的SIMD指令。例如,使用AVX2指令集的CPU可一次性处理8个32位整数,在SUM()和AVG()等聚合操作中性能提升7-10倍。
Parquet与ORC存储格式的实时场景对决在实时分析场景中,存储格式直接影响查询性能。Doris默认支持ORC格式,其字典编码和条纹索引在高基数列(如商品ID)查询中表现优异:
测试显示,在10亿条用户行为数据集中:
1. Maven依赖(兼容MySQL协议)
2. 数据源配置(application.yml)
spring: datasource: url: jdbc: username: root password: doris123 driver-class-name: com.mysql.cj.jdbc.Driver jpa: properties: hibernate: dialect: org.hibernate.dialect.MySQL8Dialect format_sql: true
3. 数据模型设计(对比MySQL表结构)
MySQL表设计(用户行为表)
sql CREATE TABLE user_behavior ( id INT PRIMARY KEY AUTO_INCREMENT, user_id BIGINT, product_id BIGINT, category_id INT, behavior_type VARCHAR(20), create_time DATETIME, INDEX idx_time (create_time) ) ENGINE=InnoDB;
Doris表设计(优化后)
sql CREATE TABLE user_behavior ( user_id BIGINT, product_id BIGINT, category_id INT, behavior_type VARCHAR(20), create_time DATETIME ) ENGINE=OLAP DUPLICATE KEY(user_id, product_id) PARTITION BY RANGE(create_time) ( PARTITION p202501 VALUES LESS THAN ('2025-02-01') ) DISTRIBUTED BY HASH(user_id) BUCKETS 10 PROPERTIES ( "storage_format" = "ORC" );
关键优化点:
@Entity@Table(name = "user_behavior")@Datapublic class UserBehavior { @Id @Column(name = "user_id") private Long userId; @Column(name = "product_id") private Long productId; @Column(name = "category_id") private Integer categoryId; @Column(name = "behavior_type") private String behaviorType; // click/purchase/collect @Column(name = "create_time") private LocalDateTime createTime;}Repository层(支持原生SQL)
public interface UserBehaviorRepository extends JpaRepository批量写入优化(支持每秒10万级写入)
@Service@RequiredArgsConstructorpublic class UserBehaviorService { private final JdbcTemplate jdbcTemplate; // 批量插入优化 public void batchInsert(List性能调优参数:从SQL到集群的全方位优化
1. 连接池配置
spring: datasource: hikari: maximum-pool-size: 20 minimum-idle: 5 connection-timeout: 30000
2. Doris集群参数调优
-- 启用向量化执行引擎SET GLOBAL enable_vectorized_engine = true;-- 优化小文件合并(减少Compaction压力)ALTER SYSTEM SET cumulative_compaction_num_threads_per_instance = 4;-- 开启Group Commit(高并发写入场景)SET group_commit = async_mode;
3. SQL优化技巧
电商平台基于Doris构建了实时运营看板,实现"用户点击-加购-下单"全链路数据的秒级更新。核心实现方案:
1. 数据模型设计
CREATE TABLE user_behavior_rollup ( dt DATE, hour INT, category_id INT, click_count BIGINT SUM, purchase_count BIGINT SUM) ENGINE=OLAPAGGREGATE KEY(dt, hour, category_id)PARTITION BY RANGE(dt)DISTRIBUTED BY HASH(category_id) BUCKETS 20;
2. 实时数据接入通过Flink CDC同步MySQL业务数据,再通过Stream Load写入Doris,端到端延迟控制在5秒内。
3. 看板查询优化
 案例二:高并发数据导入架构(支撑每秒5万条写入)
案例二:高并发数据导入架构(支撑每秒5万条写入)
某物流平台需要处理每天4亿条物流轨迹数据,传统MySQL分库分表方案维护成本极高。基于Doris的优化架构如下:
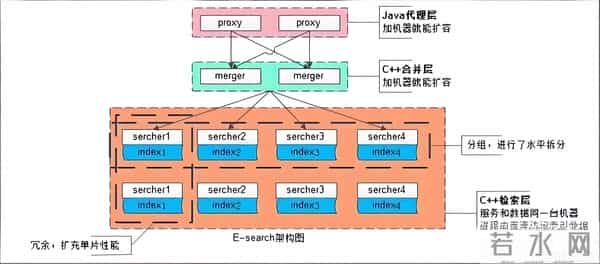
关键技术点:
场景类型
数据规模
查询特点
迁移价值
实时报表分析
千万级+
多维度聚合、高并发查询
延迟降低90%,并发提升10倍
用户行为分析
亿级+
按时间/地域/设备多维度筛选
存储成本降低70%,查询速度提升50倍
日志存储分析
TB级+
全文检索、异常检测
替代ELK stack,运维成本降低60%
业务监控大屏
百万级/天
秒级刷新、多指标展示
稳定性提升,无锁竞争问题
数据湖查询加速
PB级+
联邦查询Hive/Iceberg
查询延迟从分钟级降至秒级
迁移注意事项- 数据类型映射:MySQL的DATETIME对应Doris的DATETIMEV2,BIGINT对应LARGEINT
- SQL兼容性:Doris不支持INSERT ... ON DUPLICATE KEY UPDATE,需改用UPSERT语法
- 索引策略:Doris无需二级索引,通过前缀索引和分区裁剪优化查询
- 事务支持:Doris仅支持导入事务,不支持MySQL的ACID特性
当你的业务面临"数据量大但查询慢"、"写入并发高导致查询阻塞"、"存储成本持续攀升"这三大困境时,Apache Doris不是简单的MySQL替代品,而是实时分析架构的升级。通过MPP并行计算、列式存储、向量化执行的三重加持,Doris在保持MySQL易用性的同时,将性能推向新高度。
#Apache Doris# #实时数据分析# #Spring Boot# #MPP数据库# #性能优化#
感谢关注【AI码力】,获得更多Java秘籍!
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





