英伟达4B小模型击败GPT-5 Pro,成本仅1-36
英伟达小模型持续获胜。
ARC-AGI 2最新成绩,4B小模型NVARC以27.64%的公开榜成绩力压GPT-5 Pro 18.3%登顶榜首。
且每任务成本仅20美分,大约是GPT-5 Pro单任务成本(超过7美元)的1/36。
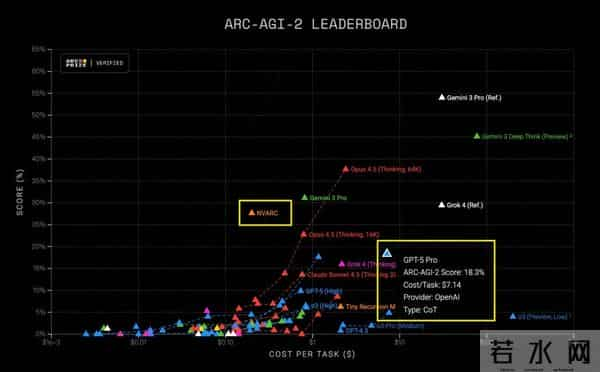
据官方分析,此次NVARC夺冠的亮点在于零预训练深度学习方法,没有依赖大规模通用数据集进行前期预训练,规避了预训练模型的领域偏见、数据依赖等问题。
而ARC-AGI 2确实是一个消除了与公共训练数据重叠的更高难度测试,主要是看测试模型能否高效地获取超出其训练数据的新技能。

成绩出炉后,官方访谈到了NVARC团队的Jean-Francois Puget和Ivan Sorokin,进行技术剖析。

快来看看“性价比之王”是如何“练”成的?
不靠参数堆料英伟达的策略是将复杂推理移至离线的合成数据管道,训练能在评估时快速运行的较小模型。
简单来说就是大规模合成高质量数据,然后对现有模型进行优化,并且将昂贵的计算工作转移到离线进行。
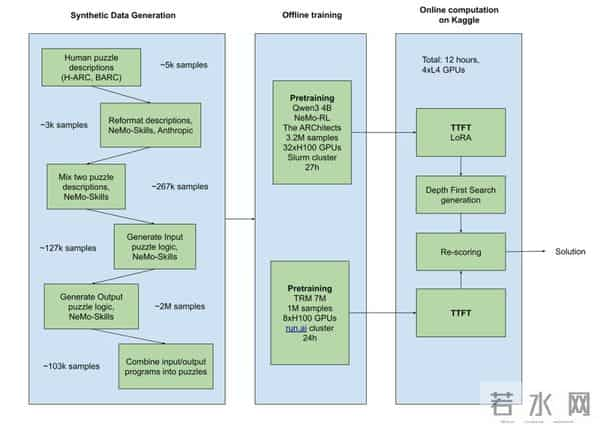
由于Kaggle比赛对计算资源限制非常严格,团队意识到,他们不能直接使用那些需要超强算力的大型LMM来进行复杂的、一步一步的推理和代码生成。
因此他们改变了思路,决定将最烧钱的计算工作转移到离线完成。比如利用GPT-OSS-120B来大规模制作高质量的合成谜题。
团队从H-ARC、BARC数据集中搜集了现有的ARC谜题数据,然后将简单的谜题混合起来,生成更复杂的新谜题。
为了确保数据质量,他们将复杂的推理管线拆分成不同的阶段,每个阶段都可以独立验证。
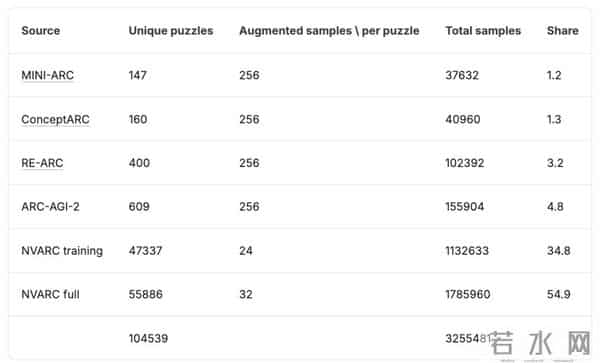
通过这种方式,他们建立了一个含320万+增强样本的合成数据集,其中每个样本最多有7对输入/输出。
这里忍不住提一嘴,哈萨比斯刚强调了Scaling Law的重要性,那么合成数据的Scaling怎么不算呢(doge)?

言归正传,NVARC核心的推理模块以改进版ARChitects方法为基础,选用小参数模型Qwen3-4B,通过对话式模板简化谜题理解。
训练时借助NeMo RL框架和Megatron后端进行监督微调。
不过,让模型取得优异成绩的关键一步在于测试时微调(TTFT)。
针对ARC-AGI-2“每个任务都是全新规则”的特点,NVARC引入了LoRA微调技术,并且是针对每一个问题都进行微调,让模型在做题前快速适应。
而对ARChitects方法的改进在于解码阶段DFS算法做了批处理优化,修复结果非确定性问题。
同时统一了8种数据增强操作评估候选解,最终在公开榜获得了27.64%的分数。
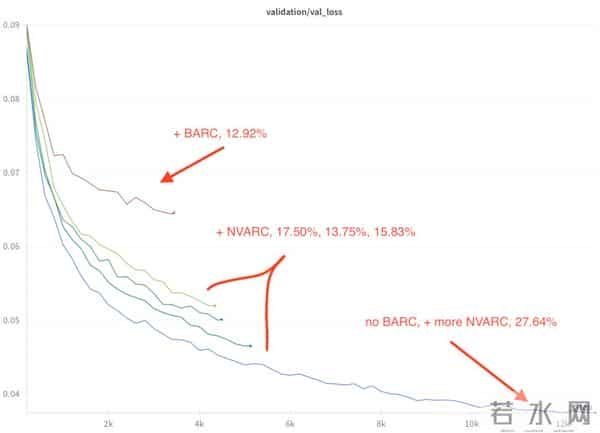
在竞赛后期,团队还应用了“少即是多”的TRM方法,尝试与Qwen3-4B集成补充分数,虽然有一定提升,但受各种限制并没有大幅优化。
那么问题来了,有人会说这样训练出来的小模型不就是做题机器吗?哪里比得上全面发力的超级大模型?
但更值得关注的或许不在于模型本身,而在于实现突破的方法。
在特定领域任务中,小模型经过针对性优化,性能并不逊色,再加之成本、速度、适配性与领域聚焦优势,它们已经在诸多场景崭露头角。
将正确的方法用在正确的地方,将会实现更大的价值。

借用这位网友所说,模型或许应该被设计得更加“敏捷”。
论文地址:
参考链接:
[1
[2
[3
本文来自微信公众号“量子位”,作者:闻乐,36氪经授权发布。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





