从分钟级等待到20倍超速:LightX2V重写AI视频生成速度上限

今年以来,开源项目LightX2V 及其 4 步视频生成蒸馏模型在 ComfyUI 社区迅速走红,单月下载量超过 170 万次。越来越多创作者用它在消费级显卡上完成高质量视频生成,把“等几分钟出一段视频”变成“边看边出片”。
LightX2V 背后并不是单一模型的优化,而是一整套面向低成本、强实时视频生成的推理技术栈:从步数蒸馏与轻量VAE,到低比特算子、稀疏算子、多卡并行与分级Offloading,目标只有一个——在主流硬件上,把视频生成推到 1:1 实时。

1:1 实时,远超现有框架
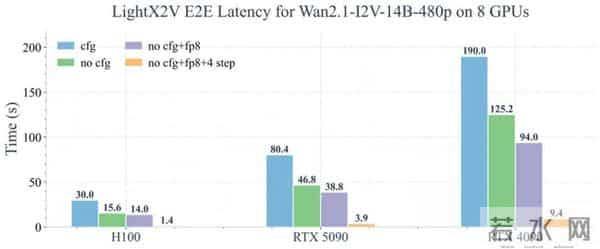
在很多视频生成框架中,生成 5–10 秒视频依然需要几分钟时间。LightX2V 在相同分辨率和硬件条件下,通过极少步数的推理和系统级优化,将生成时间压缩到与视频时长接近的水平 (如上图端到端耗时所示),实现接近 1:1 的实时体验。
在同类开源方案中,LightX2V 相比 SGLang Diffusion, FastVideo 等优秀的开源框架在延迟和吞吐上都具有明显优势 (如下图单步耗时对比所示),尤其是在 8GB–24GB 消费级显卡区间,更容易跑满硬件能力。
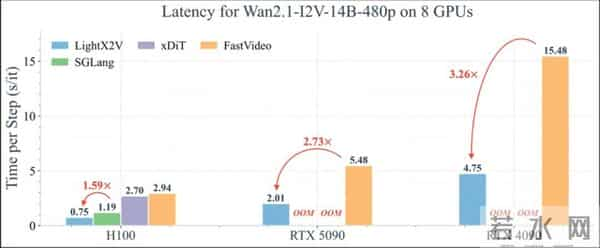
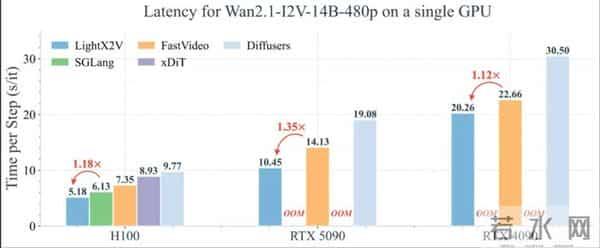
双核心算法:Phased DMD 步数蒸馏 + LightVAE
LightX2V 的速度并不是简单 “少采样几步” 得到的,而是通过两项关键算法协同设计:
Phased DMD 步数蒸馏
LightX2V 自研的 Phased DMD 步数蒸馏,把原本 40–50 步的视频扩散过程压缩到 4 步,同时保持时间一致性和运动细节。基于这一技术产出的少步模型(如 Wan2.1 / Qwen-Image 等)已经在 Hugging Face 趋势榜中长期靠前,累积下载量达到百万级。
LightVAE 轻量级 VAE
针对视频生成场景对吞吐和分辨率的双重需求,LightX2V 设计了极致轻量的 LightVAE。与常规 VAE 相比,在保持高清画质和时间一致性的前提下,有效降低了编解码开销,为 4 步推理释放出更多预算。
这两部分相当于在 “算法上先把路打通”,再让后续工程优化尽可能榨干硬件性能。
全栈性能工程:从 8GB 显存到多卡强实时
在算法压缩完成后,LightX2V 通过一套全栈推理框架,把 “能跑” 变成 “跑得快、跑得省”:
关键技术模块包括:
这些技术叠加,使 LightX2V 不仅在单机单卡上易于部署,也可以顺畅扩展到多卡集群。
模型与硬件生态:从 Wan 到国产芯片
为了方便创作者直接受益于上述优化,LightX2V 面向主流模型和硬件做了系统支持:
使用与落地:从个人创作到企业集群
在实际使用上,LightX2V 覆盖了从个人到企业的不同需求:
从图像转视频、文本转视频,到世界模型和自动驾驶仿真,LightX2V 试图用开源的方式,把 “高质量、低成本、强实时” 的视频生成能力交到更多人手里。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





