补齐SAM3最后一块短板!无需Qwen3-VL等大模型当翻译

SAM的可提示分割
SAM3 把自然图像的零样本分割能力拉到新高度,还可以使用开放词汇文本或视觉提示来检测、分割和跟踪图像和视频中的所有匹配对象。
但是 SAM3 的语义理解能力真的足够吗?如上图所示,SAM1/2 中的可提示视觉分割需要用户的多次交互提示。SAM3 的可提示概念分割只能支持短名词短语提示,无法捕捉细粒度条件,如足球运动员这类简单词。
SAM3+Agent 引入外部 Qwen3-VL 这样的大模型,将长指令转换为短名词短语,先翻译成足球运动员再执行分割,但这仍然过于粗略,丢失了原始指令中的关键细节。

我们在实际场景中可能需要的是语义理解能力更强的任意分割模型,可以根据颜色、形状和纹理等独特属性 + 上下文关系 + 动作 + 推理来检测分割物体!
为了处理更复杂的自然语言指令,比如“最右边穿蓝色球衣、正在滑铲抢球的那个球员”,一种方式是在SAM上加LLM来实现复杂语言的理解,平替版 SAM3 开源了!模型 Sa2VA 首次将 SAM-2 与 类 LLaVA 的多模态大语言模型深度融合,打造了一个统一、端到端的视觉理解系统。

今天,给大家介绍来自国内外多所大学联合的研究团队发布的 SAM3-I ——在 SAM 家族中统一了概念级理解和指令级推理,一个能让 SAM3 直接听懂复杂自然语言指令的增强框架!项目代码后续会开源、论文链接如下。原文链接:「链接」
# PaperSAM3-I: Segment Anything with Instruction# 论文 代码一、什么是可提示指令分割?
我们能否在保留 SAM3 通过大规模训练获得的强大概念召回能力的同时,使其能够解释更复杂的指令并定位相应的实例?
可提示视觉分割范式中,用户提供点、框或掩码来引导模型为每个提示分割单个目标;
可提示概念分割范式中,用户可提供“足球运动员”或“黄色巴士”等简短名词短语,使模型能够分割图像或视频中给定概念的所有实例;

可提示指令分割范式中,专门面向现实世界的使用涉及远远超出简单名词短语的表达,模型能够遵循丰富、复杂的指令,同时保持其强大的概念级定位能力。
为了让模型学会处理各种表达方式,一般将指令构建成三个层次逐渐细化的层级:
层级
示例
概念级
“足球运动员”
简单级
“穿蓝衣服的足球运动员”
复杂级
“最右边那个正要滑铲抢球的球员”
二、SAM3-I 带指令的任意分割SAM3-I 的核心目标是:在不破坏 SAM3 原有强大能力的前提下,赋予其直接理解复杂指令的能力。
整个 SAM3 主干网络完全冻结,避免灾难性遗忘,确保原有概念分割能力不受影响。这个同我们上篇文章提到的SAM3-Adapter一样,冻结SAM3的Image Encoder,只训练Mask Decoder,从而实现高效的领域迁移,将特定领域的信息或视觉提示整合到分割网络中。
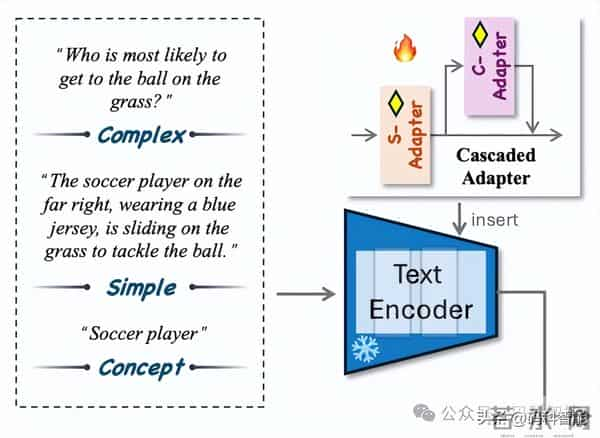
SAM3-I 在 SAM3 的文本编码器中插入了一个轻量级的级联适配模块,集成了概念级理解和指令级推理于一个高效的框架中。包含两个子模块:S-适配器,旨在处理包含显式名词短语及相关条件(如属性和空间线索)的简单指令,如处理“带颜色的狗”、“左边的人”这类简单指代;
C-适配器,基于 S-适配器,处理缺乏显式名词短语提及且需要上下文或功能推理的复杂指令,如处理“正在打电话的男人”、“准备跳起来接球的孩子”等需推理的复杂指令。两个适配器都使用瓶颈结构和多头自注意力机制,以增强与视觉特征的对齐并捕捉长距离语言依赖关系。
SAM3-I 与 SAM3 + MLLM 的定性比较。首先是简单指代指令的示例,SAM3-I 更可靠地定位预期目标,而无需依赖外部 MLLM 处理。

然后是需要上下文或功能推理的复杂指令场景,SAM3+Agent 未能生成有效的分割,而 SAM3-I 正确识别了指令对象。

SAM3-I 没有推翻 SAM3,而是为其补上了最关键的一环——指令级理解能力,文末有一些开放场景下视觉大模型相关文章。如果你正在研究多模态交互、具身智能或视觉基础模型,SAM3-I 绝对值得你重点关注。
码科智能专注于多模态大模型与计算机视觉方向,面向多个AI+场景,分享前沿算法,通用工具,开源项目及场景应用等。
从DINOv3到SAM3,Meta 到底还能给我们多少惊喜?

开放词汇检测范式再升级!IDEA重磅开源指代目标检测模型Rex-Thinker

声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





