英伟达CUDA迎来二十年来最大规模重构,开启“块级”编程新纪元

英伟达(NVIDIA)刚刚为其计算生态系统投下了一枚重磅炸弹。数小时前,这家人工智能芯片巨头正式推出了 CUDA Toolkit 13.1,并高调宣称这是该平台自 2006 年问世以来规模最大、最全面的一次技术革新。此次更新不仅标志着 GPU 编程范式的重大转变,更通过引入全新的抽象层和资源管理机制,试图彻底重塑开发者驾驭 AI 算力的方式。
在过去的二十年里,CUDA(Compute Unified Device Architecture)一直是连接英伟达硬件霸权与开发者创新能力的桥梁。然而,随着 AI 模型复杂度的指数级增长以及硬件架构的日益精细化,传统的单指令多线程(SIMT)模型逐渐显露出其局限性。CUDA 13.1 的发布,正是为了打破这一瓶颈,以适应以张量(Tensor)计算为核心的生成式 AI 时代。
CUDA Tile:抽象层级的跃升与张量计算的解放
此次更新皇冠上的明珠无疑是 CUDA Tile,这是一项旨在重新定义 GPU 核函数编写方式的革命性技术。长期以来,CUDA 开发者习惯于在 SIMT 层面进行微观操作,通过精细控制每个线程的行为来榨取硬件性能。虽然这种方式赋予了极高的灵活性,但面对如今复杂的异构计算单元——特别是专为深度学习设计的 Tensor Core(张量核心)——编写高效代码的门槛变得极高且难以维护。

CUDA Tile 引入了一种更高层级的“块级”(Tile-based)编程模型。通过这一模型,开发者不再需要纠结于单个线程的调度,而是直接操作被称为“Tile”的数据块。英伟达在更新日志中指出,新的编译器和运行时环境将自动接管繁重的底层工作,智能决定如何将这些块状数据的工作负载分发到成千上万个线程上。
这一改变的战略意义深远。首先,它极大降低了高性能算子开发的复杂度。开发者只需使用新引入的 cuTile Python 领域特定语言(DSL)或 CUDA Tile IR 虚拟指令集,定义数据块及其数学运算逻辑,系统便能自动调用底层专用硬件(如 Tensor Core 和 Tensor Memory Accelerator)的加速能力。这类似于从汇编语言向高级语言的跨越,让不具备深厚硬件背景的算法工程师也能轻松写出接近硬件极限性能的代码。
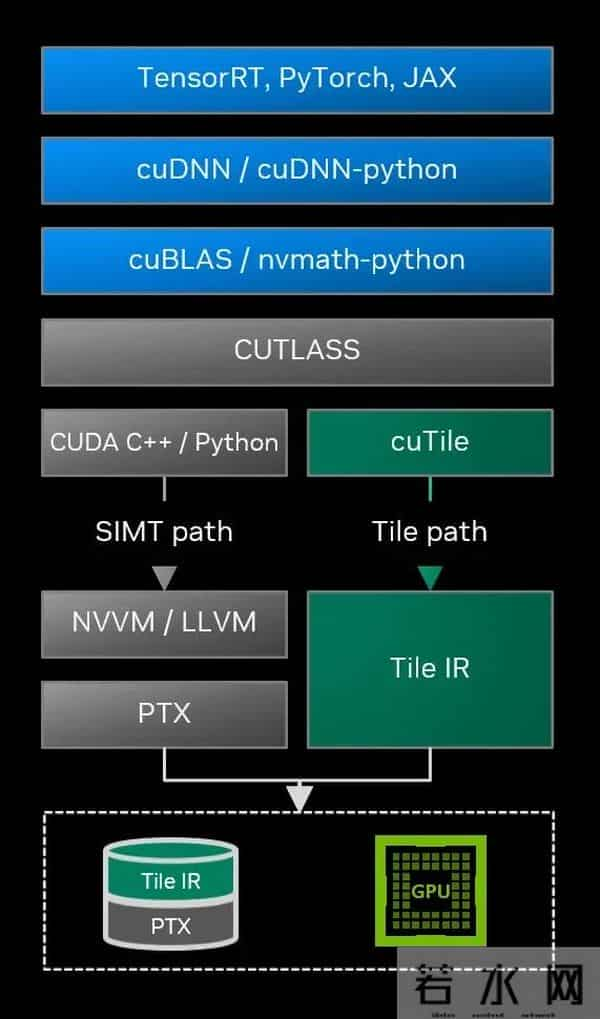
编译的 Tile 路径可以融入完整的软件栈,与 SIMT 路径对应。
其次,CUDA Tile 实现了代码与硬件架构的解耦。过去,针对不同代际 GPU(如 Hopper 到 Blackwell)的优化往往需要重写大量底层代码。而基于 Tile 的抽象层意味着,开发者编写一次代码,理论上即可兼容未来的 GPU 架构,极大地提升了软件资产的寿命和可移植性。目前,CUDA Tile 首发支持最新的 Blackwell 架构(计算能力 10.x 和 12.x),并计划在未来版本中引入 C++ 实现。
Green Context:资源调度的精细化手术
除了编程范式的革新,CUDA 13.1 在资源管理层面也祭出了杀手锏——Green Context(绿色上下文)。这是一种全新的轻量级执行环境,旨在解决多任务并发场景下的资源争抢与延迟问题。
在传统的 CUDA 上下文中,GPU 资源的分配往往较为粗放。而 Green Context 允许开发者在运行时 API 中直接创建独立的 GPU 资源分区,将特定数量的流式多处理器(SM)划拨给特定的上下文。这种机制赋予了开发者“上帝视角”般的控制力:对于那些对延迟极度敏感的关键任务(如自动驾驶中的实时推理或高频交易算法),开发者可以为其划定专属的“快车道”,确保其始终拥有可用的计算资源,而不受其他后台任务(如数据预处理或日志记录)的干扰。
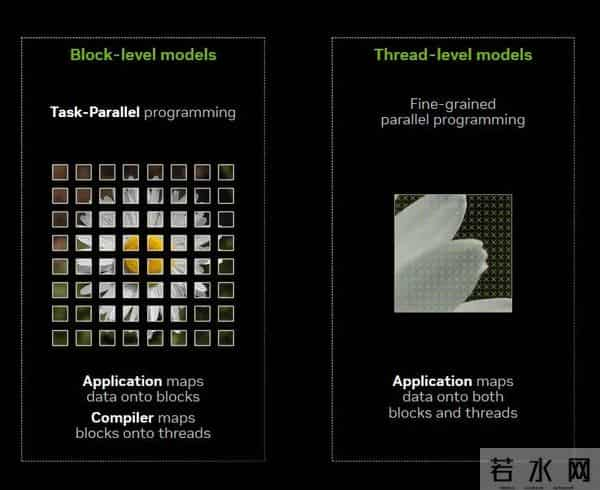
Tile 模型(左)将数据划分为多个块,编译器将其映射到线程。单指令多线程(SIMT)模型(右)将数据同时映射到块和线程
配合改进后的 split() API,开发者可以更灵活地构建复杂的 SM 分区策略,并配置独立的工作队列,从而消除不同上下文之间不必要的伪依赖。这种精细化的资源隔离能力,对于提升大型数据中心 GPU 利用率和保障关键业务服务质量(SLA)具有决定性意义。
性能监测与数学库的全面进化
为了配合新特性的落地,英伟达同步升级了其开发者工具链。Nsight Compute 分析器新增了针对 Tile 核函数的专门视图,开发者可以直观地看到 Tile 维度的管线利用率,从而快速定位性能瓶颈。同时,Compute Sanitizer 引入了编译时修补(Compile-time Patching)功能,通过将错误检测逻辑直接编译进二进制文件,实现了在极低性能损耗下的内存安全检查,能够捕捉到传统运行时工具难以发现的隐蔽内存越界问题。
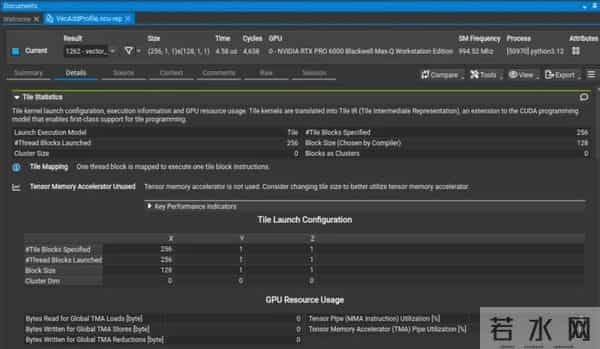
Nsight Compute 分析,重点展示了分析输出中的 Tile Statistics 部分
在基础数学库方面,cuBLAS 和 cuSOLVER 也迎来了针对 Blackwell 架构的深度优化。特别值得注意的是,cuBLAS 在 Blackwell 平台上实现了 FP4 和 FP8 等低精度数据类型的块缩放矩阵乘法加速,这直接回应了当前大模型训练与推理对低精度计算的迫切需求。测试数据显示,在特定矩阵规模下,Blackwell 架构配合新版库函数的性能相比前代 Hopper 或 L40S 实现了 1.5 至 2 倍的跃升。此外,针对科学计算领域,英伟达引入了双精度(FP64)模拟机制,使得专为 AI 设计的 Tensor Core 也能高效处理高精度科学计算任务,进一步拓宽了 GPU 的应用边界。
从底层的指令集架构到上层的 Python 接口,从资源隔离机制到调试工具链,CUDA 13.1 的发布绝非一次常规的年度更新,而是英伟达面对 AI 摩尔定律放缓挑战的一次主动出击。通过降低开发门槛、提升抽象层级并压榨硬件极限,英伟达正在巩固其坚不可摧的软件护城河,确保在未来的智能计算时代,CUDA 依然是定义“计算”二字的通用语言。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





