大模型坚持中文推理,再次证明中文数据的质量

最近deepseek发布了V3.2的正式版,性能非常不错,高性能模式可以和目前最新的闭源模型相媲美,当下中国主导的开源模型市场,可以说是和闭源模型的距离越来越接近。
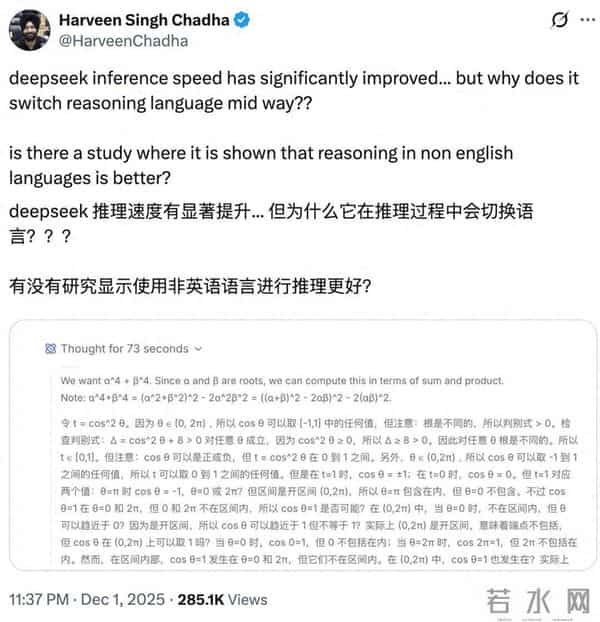
不过在研究这些开源模型的时候,有人发现了一些有趣的现象,比如说有外国开发者发现,有时候就算使用英文回答问题,答案也是英文,但是deepseek v3.2推理的过程却是中文的。
当然,这和使用模型的时候,输出答案突然出现的语言转换不一样,这并不影响使用。毕竟大家要的是结果,一部分推理模型甚至是不显示推理过程。更准确的来说,是deepseek r1在公布了推理模式的过程之后,大多数开发者才对于推理模型的逻辑有所了解,在此之前,openai的推理模型的过程是不显示的。
但是在推理过程之中,坚持用中文这个现象,确实很有趣,之前还有美国公司的模型,因为被发现推理过程使用中文,所以被认为是中国模型套壳。
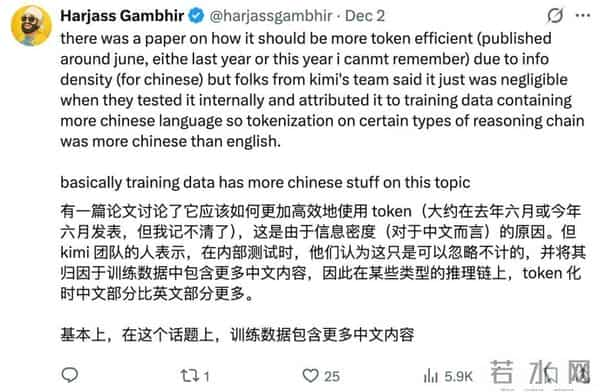
对于这个问题,我们可以给出一个解释,那就是deepseek在训练模型的推理能力的时候,用中文的时候更多。这其实是个很有趣的技术问题,现在的大模型训练,哪怕不是大厂,而是学生联手的模型,基本上都有多语言数据。但是这里指的是预训练阶段,而后续针对推理能力的后训练,情况不太一样了,可以说,为了高质量的后训练数据,终究是要选择某种语言的。
先说讨论一个问题,你认为大语言模型有推理能力吗?或者更直接一点去问,大语言模型有智力吗?在人工智能狂潮的今天,这个问题的答案似乎很容易回答,但是当冷静下来思考的时候,答案又好像没有那么明确了。既然智力是什么都没有标准答案,那么关于人工智能的定义,就更难回答了。
从最基本的机理来说,大语言模型运行的原理是概率学,通过研究各个字符之间的概率关系,使得它可以生成整段有逻辑的文字。说简单一点就是,当你和一个人特别熟悉的时候,你听到他前半句话,不需要思考就能知道对应的后半句话,大语言模型运行的机理基本上是这样的。
但是考虑到语言是如此复杂,所以大语言模型背后的概率机制,不是那么简单直观的这个字的概率是百分之几,而是非常复杂,甚至超越人类思考能力范畴的复杂函数。所以我们常常会说,大模型是一个黑箱。因为背后的机制太过复杂,以至于超过了人类理解的范畴。
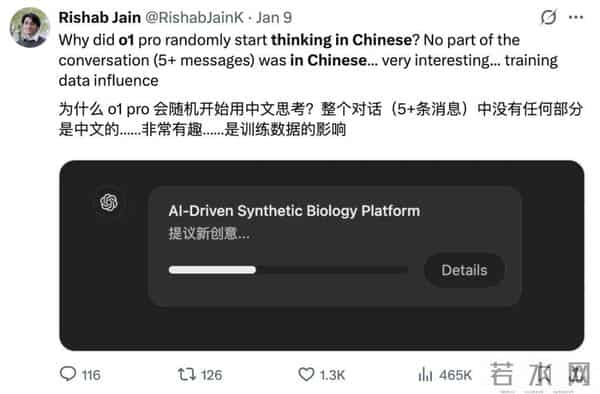
那么这种能力,到底是不是智力呢?笔者在这里不做评述,毕竟人类对自身智力的认识也就那样,而人类的智力模式是否是唯一的模式,但是这些年大家使用大模型的情况和研究来看,如果我们认为大模型存在智力,那么这种智力的模式和规律,和我们人类的思考模式是不太一样的。
在推理模型之前,哪怕是很优秀的大模型,在不调用外部插件的情况下,简单的数学题都有可能算错,因为大模型没有在计算,而是根据概率拟合;而同时,对于对过程要求高的问题,当时大模型的回答质量是有问题的,这是因为再好的概率模型,面对现实世界这个几乎无限大的空间,概率总会有失效的时候。
而推理模型提升的能力,则主要在数学和代码上面,有人甚至会觉得推理模型的写作与创意能力有所下降。这是因为推理模型并没有改变大模型的本质,而是对大模型进行特殊的后训练。用最简单的方式来说呢,大模型本质就是用概率来模仿,而推理模型,就是针对数学,代码这种逻辑性强,过程完善的东西,专门加强一段训练,使得大模型模仿推理过程更加准确。
我们都知道,大模型需要很多的数据,而其中一部分数据要进行标注,有的时候会用人工,有的时候会自动化标注。但是标注与标注是不一样的,针对推理的后训练标注,是要求很高的那种,虽然总数量会少,但是质量上不是随便找第三世界标注就能解决的,因为这部分数据不仅要求严谨专业,还需要专门的格式进行标注,传闻openai都是请各行业的专家来进行标注的,据说时薪开到了100美元以上。
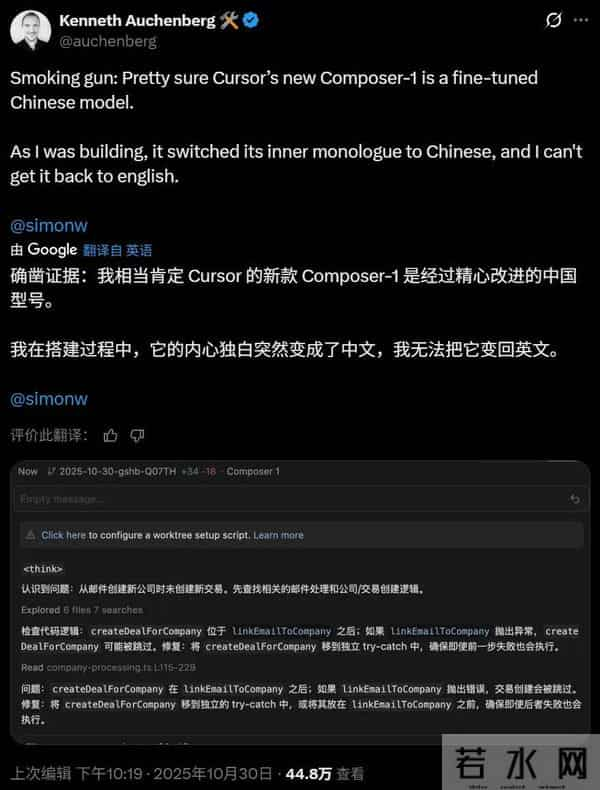
而deepseek在推理阶段使用中文,证明了deepseek在后训练的数据上,大量使用了中文。这说明了两件事情,一是中文互联网上的高质量数据并不少,二是中国的教育优势,在人工智能时代都很明显。
在这轮大语言模型浪潮之初,很多所谓的专家学者抱怨中文互联网的有效数据太少,以至于开始对中国的文化进行批判。但是这根本不是实话,中文互联网的数据是非常多的,相较于美国的差距,主要是在这轮浪潮之前,国内专门做这方面数据集的人并不多,还有就是中文互联网的格局,和美国的不太一样,这和文化没什么关系。
在中文大模型追上来之后,说这种莫名其妙话的专家就少多了。Deepseek能在多个领域打到世界顶级水平,并且推理还使用中文,证明中文互联网完全有能力提供高质量的数据,希望某些专家以后还是弄清楚情况在说话。
第二个是教育的优势,同样是在大语言模型浪潮之初,各国互联网都有一些人说什么教育无用论。但是事实证明,大语言模型时代更需要良好的教育水平,因为需要足够的知识分辨大量的虚假信息。
同时大语言模型专业能力的成长,也需要专门的训练,不仅仅是从互联网抓取数据,还需要相关领域专家去写专门的内容,而大语言模型要求通才能力,所以想要实现这一点,各行各业的水平都不能低。虽然deepseek的具体过程我们仍有未知之处,但是deepseek数据收集与标注团队的成功,显然是建立中国的教育水平上的。
事实证明,很多东西的表现形式和我们一开始设想的并不太一样,大概大多数人都没有想到,中国在计算机领域的积累,中国互联网文化的发展,还有中国教育的成果,会以大语言模型这样的形式展现出来。但是不管怎么说,中国的开源模型,都在让世界往积极的方向转变。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





