GPU算力全景:2025年AI芯片天梯图解读
北京时间12月9日,据彭博社报道,美国总统特朗普已批准英伟达向中国出口其H200 AI芯片,条件是美国政府可从销售额中抽取25%的分成。
本文对当前主流的数据中心与云端AI芯片(涵盖训练与推理)进行系统性梳理与评分,以直观的“算力天梯图”形式,呈现从最强到最弱的性能梯度。
评分采用100分制,聚焦于2025年的市场与技术规格,涵盖 NVIDIA 各代架构,包括最新的 Blackwell 以及针对特定市场的特供版本。
2025 算力天梯图(数据中心/云端AI)
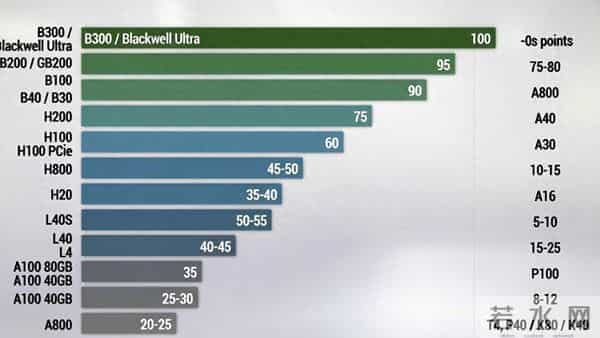
评分基准:以 2025 年最前沿的 Blackwell 架构 为标杆(100分),其他架构按综合算力、互联带宽与场景适配性进行相对评分。重点关注AI训练与推理性能。
顶尖性能(85-100分):Blackwell 架构2024-2025年发布,采用台积电4NP工艺,晶体管达2080亿,支持FP4/FP6低精度计算。
- B300 / Blackwell Ultra:100分
- 当前最强量产芯片,专为万亿参数大模型设计。
- 配备288GB HBM3e显存,带宽达8TB/s,NVLink互联带宽1.8TB/s。
- 在LLM推理性能上,较Hopper架构提升11-15倍。
- GB200(Grace Blackwell超级芯片):95分
- 集成Grace CPU与Blackwell GPU的超级芯片,平衡HPC与AI计算。
- 192GB HBM3e显存,8TB/s带宽,集成96核Arm CPU,适合Exascale级超算集群。
- B100:90分
- 标准数据中心级GPU,192GB HBM3e显存,8TB/s带宽。
- 性能远超上代Hopper,是大型AI训练的主力选择之一。
- B40 / B30(对华特供版):75-80分
- 为符合出口管制而设计的版本,NVLink互联带宽降至约1TB/s。
- 单卡算力约为B100的80%,集群扩展能力受限,逻辑类似此前H800。
主流高性能(45-75分):Hopper 架构2022-2025年主流架构,台积电4N工艺,800亿晶体管,内置Transformer引擎并支持FP8。
- H200:75分
- 当前大模型训练与推理主力,141GB HBM3e显存,带宽4.8TB/s。
- 相比H100,带宽提升30%,FP8算力达4 PFLOPS。
- H100(SXM版):60分
- 2023-2025年行业基准芯片,80GB HBM3显存,带宽3.35TB/s。
- 提供2 PFLOPS FP8算力,NVLink互联带宽900GB/s。
- H100 PCIe版:55分
- 规格与SXM版相同,但受PCIe接口限制,带宽与功耗较低,集群能力较弱。
- H800:45-50分
- 对华特供版,80GB HBM2e显存,带宽约2TB/s。
- 算力接近H100,但NVLink带宽降至400-480GB/s,导致集群效率下降约40%。
- H20:35-40分
- 为符合出口管制进一步降配,提供96GB/141GB HBM3显存变体。
- 总算力仅约为H100的15%,主打高带宽、低算力场景,仍支持900GB/s NVLink。
推理与专业视觉(20-55分):Ada Lovelace 架构2022-2025年推出,侧重AI推理与可视化,并非纯Tensor Core设计。
- L40S:50-55分
- 48GB GDDR6显存,FP32性能为A100的5倍,支持AI推理与3D渲染。
- 带宽864GB/s,适合AI推理与虚拟化混合负载。
- L40:40-45分
- 与L40S规格相似但未进行专项优化,适用于虚拟工作站及中小模型推理。
- L4:20-25分
- 低功耗边缘推理卡,24GB GDDR6显存,TDP仅72W。
- 效率约为旧款T4的2倍,适合部署在能受限的环境。
上一代主力(5-35分):Ampere 架构2020-2023年主力架构,台积电7nm工艺,支持MIG虚拟化与稀疏计算。
- A100 80GB:35分
- 上一代数据中心基础芯片,80GB HBM2e显存,带宽2TB/s。
- FP16算力312 TFLOPS,NVLink带宽600GB/s。
- A100 40GB:30分
- 显存减半,在大模型任务中处于劣势。
- A800:25-30分
- 对华特供版,NVLink带宽降至400GB/s,集群效率下降约30%。
- A40:20-25分
- 48GB GDDR6显存,兼顾AI推理与专业图形渲染。
- A30:15-20分
- 24GB HBM2显存,强在多实例GPU(MIG)虚拟化与通用AI计算。
- A10:10-15分
- 中等功耗推理卡,24GB GDDR6显存,TDP 150W。
- A16:5-10分
- 适用于虚拟桌面基础设施(VDI)与多实例场景,16GB GDDR6X显存。
历史架构(<20分):Volta / Pascal / Kepler 等早期架构,目前多用于历史负载或轻量推理。
- V100:15-20分
- Volta架构代表,首代Tensor Core,32GB HBM2显存。
- 仍可勉强运行部分大模型,但效率已不占优。
- T4:10-15分
- Turing架构,低功耗边缘推理卡,INT8性能强,适合轻量级部署。
- P100:8-12分
- Pascal架构,传统HPC场景,无Tensor Core。
- P40 / K80 / K40 等:<10分
- 更早的架构,仅适用于小模型或历史遗留负载。
扩展说明与覆盖范围- 架构覆盖完整:包含专为推理优化的Ada Lovelace L系列,以及Grace Hopper超级芯片(如GH200,可视为H100+Grace CPU的系统级方案,在扩展性上额外加分)。
- 特供版说明:所有针对特定市场(如中国)的型号(B30/B40、H800、A800、H20等)均主要在NVLink互联带宽上进行限制,单卡推理性能影响较小(通常<10%),但会严重影响多卡训练集群效率(下降30-40%)。
- 边界说明:本文未包含消费级GeForce显卡(显存与驱动不适合数据中心),也未包含纯CPU产品(如Grace)。总计覆盖近30款AI相关GPU,聚焦云端与数据中心场景。
评分综合考量算力、显存、带宽、互联及能效,针对2025年AI工作负载(尤其是大语言模型)优化。实际表现可能因软件、模型与系统配置而异。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





