如何看待最新发布的国产统一多模态大模型让P视频像P图一样
一、前言:
P视频像P图一样简单,其实我刚开始听到这句话是有点疑惑的。
不过,最近我也也注意到这个工作了。就是在这周内,快手可灵 AI 正式发布的新一代多模态创作工具「可灵 O1」,而且试了下,感觉解开了不少疑惑。
其实,我自己之前是写过几次可灵使用体验的 [1] [2] [3] ,对这个产品一路走来也算了解不少。
从去年六月份的3分钟图生视频和视频续写,到后面海内外的全面内测,到今年上半年上了政府工作报告吹风会,以及昨天发布的「可灵 O1」。
可以说,我见证了可灵的一路成长~
因此,我觉得「可灵 O1」自己也有必要看一看,试一试,简单体验一下~
长期关注我的朋友都知道,我一直都很持续关注大模型的发展,也会经常通过回答和想法来测试大模型,以及分享大模型的使用体验。
据我所知,这应该是全球首个将视频生成与视频编辑统一在同一模型中的大一统多模态视频模型。它能够同时理解文字、图片、视频、主体等多种输入,将过去需要在多个工具、多个插件之间切换的创作步骤,全部收束到一个统一的全能引擎之中。这是过往飞大一统的工具所无法贯彻的。
在我看来,正如题目所述,可灵 O1 要解决的是视频创作中最典型、最顽固的痛点,即角色与场景一致性的问题。它的出现,让视频不再是「剪出来」的,而是可以像 P 图一样自然地「改出来」「说出来」的。
二、为什么需要「大一统多模态视频模型」在我看来,过去的 AI 视频工具给人带来了很多惊喜,但也有一些突出的问题亟待解决:
例如,一致性低,导致角色前后不一样,场景时空跳变明显;
再比如,生成与编辑割裂,生成要用 A 工具,编辑要用 B 软件,拼接靠 C,导致制作人员操作流程很繁琐。
最后,就是多模态能力分散:文字生成、图像生成、视频编辑各自独立,无法统一表达创作意图,导致哪怕创作者再集中主题,最后呈现的效果都不会达到完整的统一性。
其实,在我看来,这三个有一点共同,那就是「单一」。要么是单一场景之间跳变割裂,要么是单一工具,以及单一多模态能力,各自为营。
而「可灵O1」,则对此做出了全面的改变。
其基于MVL(Multi-modal Visual Language,多模态视觉语言)理念,打破了传统单一视频生成任务的模型边界,将参考生视频、文生视频、首尾帧生视频、视频内容增删、视频修改变换、风格重绘、镜头延展等多种任务,融合于同一个全能引擎之中,使得用户无需在多个模型及工具间跳转,即可一站式完成从生成到修改的全部创作流程。
依托可灵视频O1模型的深层语义理解力,用户上传的图片、视频、主体、文字——在「可灵O1」眼中,皆是指令。
这正对应了目前的创作痛点,影视剧需要的是连贯角色、统一风格、可控镜头,而类似我这样的个人玩家,或者说内容创作者,需要的则是说一句指令、加一张图和提示词就能开始创作。
就这些方面,「可灵O1」可谓完美适配~
三、核心能力与玩法第一点,就是我前面提到的:在「可灵O1」眼中,一切内容皆是指令。
举个例子,我下面这一条,有图片(其中「林黛玉」为主体),有视频,还有我写的提示词「在视频里,让林黛玉和图片1一起跳舞 。」
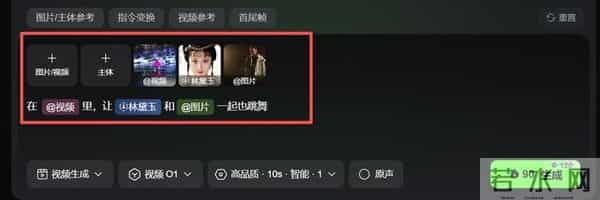
可见,对于「可灵O1」,图片、视频、主体、文字,皆是指令。
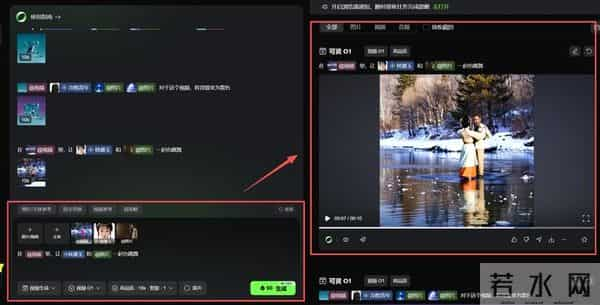
可以看看我创作的这个视频,完全遵循了指令,以及运用了我的素材:

其次,就是可灵的一致性能力了。
一致性,是决定一个视频能否真正用得上的基石,可灵 O1 在一致性上的突破是全面的。
例如我下面的例子,同一人物在不同场景下的连续镜头,可以看到,角色保持了高度的统一性,这是以往模型所无法做到的。


接着,可灵 O1 不止能生视频,更能修改视频,而且是通过对话式指令 + 多模态输入来轻松修改 。
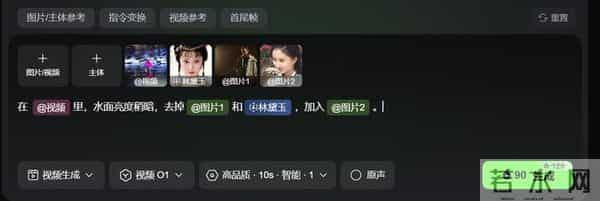
例如我上面的提示词修改,其生成作品如下:

通过指令变换,降低了湖面颜色,删除了视频的林黛玉和老白,新增了指定的少女图像角色在跳舞。
可以说,其完全将繁琐的剪辑后期变成了简单的对话,一句话即可读懂影像逻辑,从局部的主体替换,到整体的视频风格重绘,自动完成像素级的语义重构。
无论是背景的改变,内容的删除、增加和修改,都可一并完成。
一句话来形容:剪视频,变成了个人意图的表达。
四、展望我个人认为,「可灵 O1」最重要的意义在于:对于普通创作者来说,视频制作,不再是剪出来的,而是想出来与说出来的。
也就是说,创作者的能力重点,从掌握工具 → 清晰表达意图,从会剪辑编程了你会清晰表达即可。
可以说,这将大大降低视频创作的难度,将视频制作将变成一件更自然、直观的事情。它所实现的是彻底解决一致性,让 P 视频像 P 图一样简单。
无论是影视、自媒体、还是电商广告,都将因可灵 O1 的一致性与可控性而收益。
如果让我来展望一下其未来的话,我感觉「可灵 O1」不只是一个功能集合体,未来更有可能是下一代视频创作的基础设施。
未来可期,再接再厉~
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





